
良い本か?と問われれば良い本だと思いますが、咀嚼するのも難しいだろうなぁと思いました。
 嫌われる勇気
嫌われる勇気- アドラー心理学ではトラウマを明確に否定する
- 健全な劣等感とは、他社との比較の中で生まれるものではなく、「理想の自分」との比較から生まれる
- 承認欲求は危うい、われわれは「他社の期待を満たすために生きているのではない」
- 他者の課題には踏み込まない
- 「アメとムチ」はどちらも背後にある目的は操作
- 子供が勉強すること、これは子供が自ら解決すべき課題で会って親、教師が肩代わりできるものではない
良い本か?と問われれば良い本だと思いますが、咀嚼するのも難しいだろうなぁと思いました。
先週はCBI年会に参加していました。
初日の火曜日はキリンシティホール
二日目の水曜日は春菜でハゼの唐揚げ
三日目の木曜日は大松でイワシ
金曜日は経営層に近い若い方々と綾ですき焼きというハードな一週間でしたが、たくさん学べたので良かったです。
で、金曜に話したことがちょっと残っていて、このツイートを読んで考えさせられたことです。
現場の人は無邪気にサイエンスをするのが仕事で、一方で「どうしたら、それテーマ化できるかな?ビジネスにできるのかな?」て考えるのがマネジメントの仕事かなと思います。
— kzfm (@fmkz___) October 29, 2022
まぁでも無邪気なままでは狭い世界しか見えない気もします。
例えばプロジェクトを10個走らせて、「サイエンティフィックに熟慮してやめるべき」と早期に10個終わらせるのは現場の人は褒められるべきことだけど、成果としては0なのでマネジメントとしては無能の証拠なわけです。
研究職の人達はたいていどこかで管理職に上がっていくので、そのキャリアパスの中でどこかでビジネスを強く意識したマインドにドラスティックに変えないとならないポイントが有るように思うんだけど、そんなの研修とかでいちいち習わないから、暗黙のうちに理解することを期待されているような気がします。
となると実際のところ、無邪気なまま大人になる管理職もいるわけで、そういう人は成果を出さないことを特に問題だと思わなかったり、ちょっとストレスが加わると数値目標を満たすことを目標にしがちになるなのかなぁと思ったりするわけです。管理職は数字をコンスタントに達成できるような強い組織づくりを要求されているのに、無邪気系管理職はそこまで思いが至らないような感じがします。
なかなか難しい問題ですねぇ。
こんな感じのお話をしてみました
私のスピーチ、専門職志向の人には結構刺さったようで何よりです。
— kzfm (@fmkz___) October 24, 2022
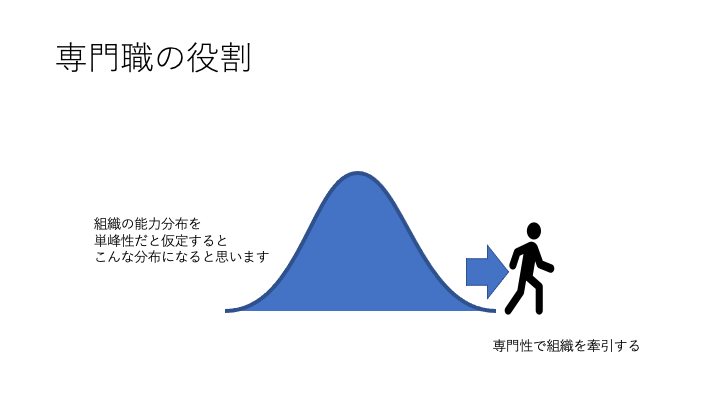
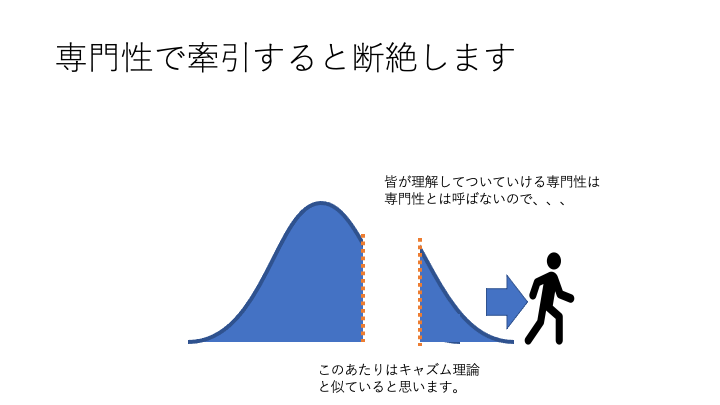
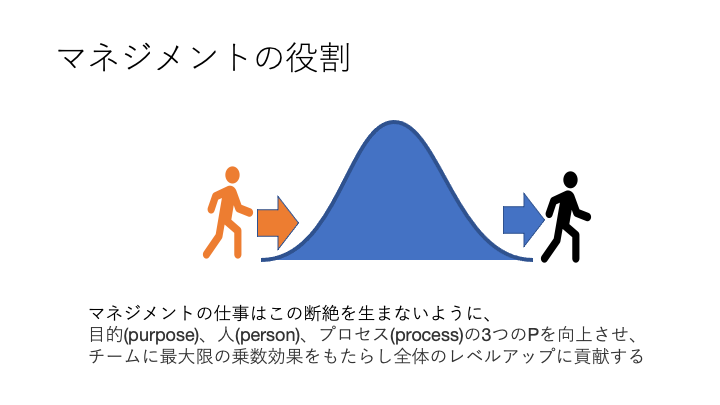
この話を「 断絶具合は専門性の証なので、専門職は断絶を恐れずより深い断絶を目指して自分を高めていくべき」というように受け止めた専門職の人もいましてそれは正しいと思います。私も結果としてほぼ理解者がいなくなり前職に飽きて転職したわけですから、、
というわけで、大阪に日帰りで行ってきました。
会に間に合うように出て終わったら帰ってくるだけなので、とりあえず、新大阪駅構内の神座で「美味しいラーメン」を 食べたくらい。あとはお土産をいろいろ買った。
米寿の祝の参加者が60人弱だったそうで、先生の人徳故なんでしょう。私は(というか私のいた学科は)必然的に2つのラボに所属するので、教授が二人いますが、その分コネクションが今になって生きてきています。
久々に同窓の人たちと交流を温めることができたのと、他社の内部の情報とか、いろいろ面白そうな情報を交換してすることができて大変良かったです。
そして今、この帰りの新幹線の中で、ブログを書きつつ明日のスピーチの内容を考えています。
「攻撃的なマネジメントがいて仕事がやりづらい」とか「話の通じない同僚がいて生産性が上がらない」とかいうのはよくある組織の悩みで、一般的な会社でも労働組合からもイシューとして上がってくるし、人事からも指摘されるし、雑談していてもあがる話題かなぁと思います。
あまりにも多いので、日本版ビジョナリー・カンパニー2は「誰を(幼稚園)バスにのせるか?」なのかなぁと皮肉りたくなりました。
自分としては、たまにパスを停めて、食事でもしながらコミュニケーションを取って、あまり日々の仕事でギスギスさせないというのが理想なのかなぁと思うのですが、、、
日本の会社だと特に誰をバスから降ろすかという議論はしにくいように思いますが、いずれせざるを得なくなると思いますので、お互いを尊重して仕事をするというのは心がけておくべきじゃないかなぁと思います。
私もより良い人材に入れ変えて強い組織を目指すのが健全だと思っているのですが、なかなか難しいですねぇ
夕方昼寝をしてしまい、眠くならないので最近考えたことを書き出しておきます。
先日、専門職のステージが一つあがりまして(詳しくはlinkedinでも見てください)HRやエグゼクティブにお祝いの会を開いてもらいました。そこで、席が隣の人事の方から「私さんはどうやって成長したんですか?人材育成の観点から興味があるんですけど」と質問されたので、「よくわかんないですねー、若いときにはまわりがドン引きするようなハードワークはしてました(させられていたが正しいのだけど)けどねー」と無難な答えを返しておきましたが、あとから考えて見るに、これは 自分が人材育成をしていくためにもよくよく考えてみるべき深い問い であるような気がしたので、ここ何日かずっと考えていました。
上司に恵まれたっていうのはもちろんあって、元ノバルティスの研究所長とかファイザーの人から色々と教えてもらうことができたのはラッキーだったと思いますが、自分はその当時何を考えて働いていたのだろうとおもいかえそうとしたところ「考えてみたらログ取ってあるじゃん、workタグを過去に遡ればいいじゃん」となり追いかけた結果、会社入ってから結構本を読んでよく考えていたなぁということに気づきました。で、自分の考えを形作ったような本をピックアップしてみました。
最近はちょっとブログを書く余裕ができているので忘れないうちにメモっている。大体10年前に考えたことが今役に立っているので10年後に役にたつはず。
— kzfm (@fmkz___) October 3, 2022
当たり前ですが論文は読書以上に読んでいます。特に批判的に読むようにしていました。
あとはプレゼンテーションに関しては当時から態度を明確にしていて、専門領域の内容を専門外の人たちにいかにわかった気にさせるかというのは必須要件としてプレゼンに臨んでいます。逆にそれができないと、昇進はできないと思いますというか思い知らされました。
余談ですが、部下の人たちには「話したいことを話すのではなくて伝えるべきことを伝えてください」とお願いしているのですが、これをうまく英訳できなくて困っています。DeepLにかけるとどっちもtellになってしまう、、、だれかいい訳を知っていたら教えて下さい。
それから昔からこういうことを考えていたらしく、今はこの組織を弄る実験に夢中なので、優秀層を引っ張って伸ばすという専門職としての役割と、後ろから押して全体の底上げを行うという部長の役割が一緒にできてそれなりに楽しく働いています。ちなみにこのエントリはその当時の組織のITリテラシ向上(いまでいうDX)をさせられたときに、低層のサポートに時間を使うのが嫌すぎて自分を納得させるためにロジックをこねくり回したときのものだ記憶していますw
チョロQはゴールから現在地まで引っ張ることでゴールを超えて進んでいく乗り物 だと思います。
組織の現状をよく把握できている人はネガティブな意見を言いがちだと思います。見えている理想と現実のギャップを正確に把握できる能力が有るので当たり前といえば当たり前なのですが。
ただ、それをこのギャップを超えていこうという人達はそのギャップをバネにというかゼンマイのように推進力に変換して乗り越えていくような才能があると思います。そういう人達の現状批判は結構面白いし、どのように未来を作り出すのかなーというワクワク感がありますし、成果という形で示すことが多いでしょう。
問題は、「このギャップがきちんと見えているにも関わらず、不満とか文句を言って改善の行動に移せない人」と「ムダにポジティブだけどギャップを理解していない人」達かなぁと思っています。
前者はただ場の雰囲気を悪くするだけなので害悪といえばそのままなのですが、前向きな行動さえ取ってもらえれば力強いので伸びしろは有ると思うのですが、後者はどうなんかなぁと思っています。
09102022 chemoinformatics bioinformatics
GID4に強く結合する化合物を探索するためにフラグメントスクリーニングしたりDELを使ったりするというストーリー
そもそもGID4は結晶構造が取られている上に基質認識のために深いポケットが有ることがわかっているというかFDVSWFMGというデグロンというペプチドを認識することがわかっているので、フラグメントスクリーニングの確度がちょっとあがっているから良い戦略だなと思いました。
ただフラグメントスクリーニングで得られた化合物の結合能はサブuMとそれほど高くなかった。
それとは別にDELを使ったスクリーニングをしているのだが、非天然アミノ酸trimerって感じの戦略なのでうまくペプチドミミックを選んでいるなぁと思いました。まぁそれはみなさんがDELをイメージしているかは別としてGID4の認識能をうまく利用したスクリーニング戦略だなぁと思いました。
さて、E3リガーゼはミスフォールディングを認識すると言われますが、ミスフォールディングって何かなぁと考えると「正しくないフォールディング」ってなるわけで、それって何?っていうのがSBDDとか構造生物関連の人には定義ちゃんとしろよーとか思われると思うのです。
私の解釈だと、「本来蛋白質の3次元構造のパッキングに寄与する疎水性残基が蛋白表面に露出してしまっている」とか「ペプチドの主鎖がうっかりみえてしまっている」とかそういうのがミスフォールディングとして認識されるのかなぁと思っているのでDELで非天然のアミノ酸様トリマーを合成するのはわかるんだけどそれはペプチドなぞってないか?とズルいというか言葉遊びをしているのではないかという気はちょっとします。
それだったらペプチドスクリーニングから論理的に設計して低分子の転換を目指すのが王道っていうか正しいサイエンスなんじゃないかなーと思ってます。ペプチドの相互作用から低分子化目指してスボレキサントまでたどり着くようなイメージですが、、、
職場で怒りを覚える状況というのは、部下が自分の期待通りの結果を出さなかったという「期待と現実の不一致」に対してが多いかと思います。このあたり仏教法話から拝借してます。
そんなトラブルは日常茶飯事ですが、私の場合はサイエンティフィックな仕事でそういう怒りを覚えることが多いみたいです。そもそもマネジメントスキルはそんなに高くないことを認識しているので、なんか素直に受け入れていますが、サイエンティフィックなレポートに論理性がなかったりすると、「この程度のことも?」ってイラッとします。まぁ局所的には論理的だけどいくつかの事象をつなげると破綻するっていう人は結構多くて、全体に一貫性をもたせられるっていう人ってほんの一握りだなぁとは理解しているので、自分勝手な期待感を相手に押し付けた結果の怒りであることは認識しているのであとから反省しています。さすがにそれをそのままぶつけることはないのですが、反省する前に気づけよって自分に突っ込んでます。
さて昔のマネジメントだとこういう場合には上司が怒ることで、「期待と現実の不一致」を部下が認識してそのギャップを埋めるべく頑張るというのが定番だったように思いますが、現在ではそのような悪しき風習は廃れています。 怒ったりイライラしたところで、結果が改善するわけでもなくただ単に部下が不愉快な思いをするだけでしょう。
今どきのマネジメントは事実の指摘だけにとどめてわざわざ叱ることはしません。実際最近のビジネス本はそういうことが書いてあることが多いです。部下を尊重して部下のありのままを受け入れるタイプのマネジメントが主流かなぁと思います。
ただし、この状況は随分ハイコンテクストに寄っているなぁと個人的には思います。何が足りないかを自分で自己分析できる人しか成長できない職場はそれはそれで不健全な気がするけどなぁと思っています。なんか「ダメなやつはなにをやってもダメ」を暗黙的に肯定しているような気がしてちょっと気持ち悪い。
それとも心理的安全性が保証されている職場はローコンテクストが受け入れられやすいから健全ということなのでしょうかね?
富士にもできたのねってことで早速行ってきました。
羽田空港使うときには湊屋は外せない系なので、近所にアレ系の店ができたのはよいですね。ぜひ続いてほしいです。
先週、長かった私のタスクも一段落して落ち着いたのもつかの間、上司との1on1ミーティングで新たな宿題を与えられ(それ1on1なの?というツッコミはおいといて)週末は色々考えていました。まぁ4回目摂取してどこにも行く気にならなかったのでちょうどよかったのですが。
というわけで、 「率直に意見できるチームであればSOTAを超えられるのか?技術レベルを高められるのか?そんな甘いもんじゃねーだろ、サイエンスはよぉ(意訳)」 ってのが上司の問いかけで、私はこの問いにマネジメントで答えなければならんなー、さてどうしようかなぁというのが今週末の悩みです。
確かに、個々のスキルが高い人間でチームを組んでも心理的安全性が保証されてないとうまくいかないっていうのは明らかなんですが、逆に心理的安全性が高いチームが技術の劣る単なる仲良し倶楽部っていうだけの可能性も大いにありますなぁと。そういうチームってどうやったらより高い目標を目指すようになるんでしょうねぇ。
やはり向上心のあるいい人をバスに乗せるのが必須なんだろうなぁと考えているので、下記条件に当てはまっていて転職を考えているとかちょっと話してみたいなぁという方がいればぜひお話させてください。今月はCBI年会でウロウロしていると思いますのでそっちで直接声をかけてくださってもいいです。
 ビジョナリー・カンパニー2 飛躍の法則
ビジョナリー・カンパニー2 飛躍の法則 チョロQ e-09 フォルクスワーゲン タイプ 1
チョロQ e-09 フォルクスワーゲン タイプ 1