
自分や家族が風邪ひいたり、雨や雪が降ったりとかであっという間に三週間ほど過ぎてしまったが、一日かけて耕した。


二年目の明日葉は新芽を摘んで天麩羅にして食べた。
あとは、石灰撒いて、肥料入れればいいかな。
自分や家族が風邪ひいたり、雨や雪が降ったりとかであっという間に三週間ほど過ぎてしまったが、一日かけて耕した。
二年目の明日葉は新芽を摘んで天麩羅にして食べた。
あとは、石灰撒いて、肥料入れればいいかな。
18042010 Scala
Pythonで書いたシンプソン積分をScalaでも書いてみたのだけどfor yieldで総和を求めるやり方が分からなかったので(RandomAccessSeq.Projectionとかいうのが出た)結局var変数で。
def simpson(f: Double => Double, a: Double, b: Double, n: Int): Double = {
val h = (b - a)/n
var sum = 0.0
for (i <- 0 to n-1) {
sum = sum + f(a+i*h) + 4.0 * f(a+i*h+h/2) + f(a+i*h+h)
}
sum * h / 6
}
def func(x: Double): Double = {
1.0 / (1 + Math.pow(x,2))
}
実行
scala> simpson(func, 0, 1, 1000)
res24: Double = 0.7853981633974496
Int,Double,Floatとかの型の使い方もいまいちわかってないな。
16042010 Python
をシンプソン積分で解けってのがあった。
def simpson(f,a,b,n=1000):
h = float(b-a)/n
return (h/6)*sum([f(a+i*h)+4*f(a+i*h+h/2)+f(a+i*h+h) for i in range(n)])
if __name__ == "__main__":
print simpson(lambda x: 1.0/(1+x**2),0,1)
これをjythonで実行すればJavaの課題を解いたことになるのではないか?
15042010 PRML
biopythonで。
#!/usr/bin/env python
# -*- encoding:utf-8 -*-
# kzfm <kerolinq [AT] gmail.com>
def pm2bib(pm):
author = "; ".join(pm['AU'])
year = pm['DP'][0:4]
bib = """@article{PMID:%s,
author = {%s},
title = {%s},
journal = {%s},
year = {%s},
volume = {%s},
number = {%s},
pages = {%s},
}
""" % (pm['PMID'],author,pm['TI'],pm['TA'],year,pm['VI'],pm.get('IP',""),pm['PG'])
return bib
if __name__ == "__main__":
from Bio import Entrez, Medline
Entrez.email = "xxx@gmail.com"
record = Entrez.read(Entrez.esearch(db="pubmed",term="biopython"))
idlist = record["IdList"]
records = Medline.parse(Entrez.efetch(db="pubmed",id=idlist,rettype="medline",retmode="text"))
for record in records:
print pm2bib(record)
適当に用意したtex
\documentclass{jarticle}
\begin{document}
\bibliographystyle{plain}
「お互いの犬\cite{PMID:20015970}の写真\cite{PMID:19811691}を撮り合い、帰ったらその写真\cite{PMID:19773334}
を自分のブログ\cite{PMID:19304878}にUPして紹介\cite{PMID:18606172}
し、お互いのブログにお礼コメント\cite{PMID:16403221}をするというのが暗黙のルール\cite{PMID:16377612}です。」
X06HT予約しにいったら、携帯電話が妻名義\cite{PMID:14871861}だったので予約出来なかった。
あと名義変更に一日かかるからあと二回いかないと予約出来ない\cite{PMID:14630660}
という衝撃の事実を聞かされた。多分、アンドロイドへの何か\cite{PMID:12230038}
が試されているんだろう。
\bibliography{test}
\end{document}
できたpdf
14042010 PRML
パターン認識と機械学習を読み直していて今4章。
図4.7のパーセプトロンのイメージが大変わかりやすいことに気づいて感激したのであった。
いまは、Pinheiroを読むのに苦労している。
 Mixed-Effects Models in S and S-PLUS (Statistics and Computing)
Mixed-Effects Models in S and S-PLUS (Statistics and Computing)これをきちんと理解しないと、PK-PDが進まないんだよな。
 Pharmacokinetic-Pharmacodynamic Modeling And Simulation
Pharmacokinetic-Pharmacodynamic Modeling And Simulation余計な変数多いな。
public class SkiFriction {
public int bestPosition(String sF, String pF) {
int sFl = sF.length();
int pFl = pF.length();
if(sFl >= pFl) return 0;
int result = 0;
for(int i=0;i<pFl-sFl;i++) {
int lmax = 0;
for(int j=0;j<sFl;j++){
int k = sF.charAt(j) - '0'+ pF.charAt(i+j) - '0';
if(k>lmax) lmax = k;
}
result += lmax;
}
return result;
}
}
数字の比較はMath.max使えばいいのか
11042010 java
reverseってメソッドはないのかな? 両方ソートして、一方は先頭から他方は後ろから掛けてsumを求めた。
import java.util.*;
public class RoyalTreasurer {
public int minimalArrangement(int[] A, int[] B) {
java.util.Arrays.sort(A);
java.util.Arrays.sort(B);
int result = 0;
for(int i=0;i<A.length;i++)
{
result += A[i] * B[A.length - i -1];
}
return result;
}
}
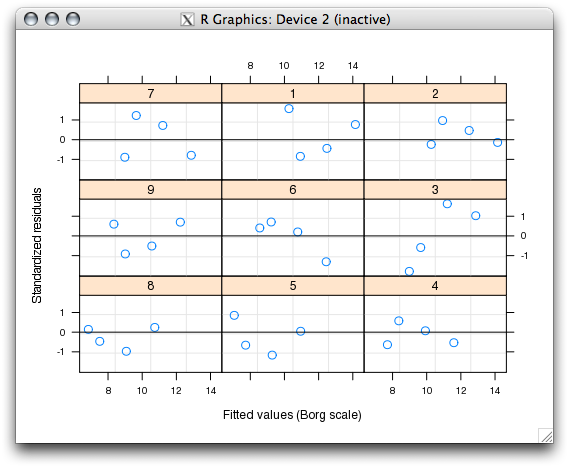
11042010 R
nlmeを使いこなすために。
 Mixed-Effects Models in S and S-PLUS (Statistics and Computing)
Mixed-Effects Models in S and S-PLUS (Statistics and Computing)ergoStoolのサンプルを。
residual plot(p.21)
 藤田智の菜園スタートBOOK 春夏編 (生活実用シリーズ NHK趣味の園芸/やさいの時間)
藤田智の菜園スタートBOOK 春夏編 (生活実用シリーズ NHK趣味の園芸/やさいの時間) Jythonプログラミング
Jythonプログラミング パターン認識と機械学習 上 - ベイズ理論による統計的予測
パターン認識と機械学習 上 - ベイズ理論による統計的予測