
主催者がHaskellerではないので「三島Haskell無名関数の会」と銘打ってますが、正確には三島λerの会です(嘘です)。
というわけで、Haskell (とPython)でおおいに盛り上がりましょう。
λ.ΣπとかいうHaskellとPythonを主軸にした地域コミュニティでもつくるかっていう話をしてこようっと。
主催者がHaskellerではないので「三島Haskell無名関数の会」と銘打ってますが、正確には三島λerの会です(嘘です)。
というわけで、Haskell (とPython)でおおいに盛り上がりましょう。
λ.ΣπとかいうHaskellとPythonを主軸にした地域コミュニティでもつくるかっていう話をしてこようっと。
24092012 life
戦略として周知されてしまったら、知らないと大損するだけで知っているからアドバンテージが生じるという話にはならんと思うが。
内容はよくまとまっているので、速読にちょうどよかった。
ブルーオーシャンとかレッドオーシャンとか表現すると、まだ見ぬ土地が眠っているみたいに錯覚するけど、レッドを突き詰めて考えていった結果新たな視点が開けるみたいな、視点の転換と新たな顧客想像の結果がブルーだったっていうだけの話で、プロスペクティブにやれんのか?という疑問はつきまとうなぁ。
メディシナルケミストリー系の論文のresult&discussionみたいだw
23092012 Ti
Twitterクライアントの作成をアプリ作成の入門にするのも下火になりそうだし、面倒くさくなる前に作ってみた。お盆のあたりからだらだらコードを写経してたので1ヶ月もかかったが、3,4章のTwitterクライアントまではできた。
4-3-2で紹介されていたキーボードツールバーが動かなくて困ったが、元のソースコードをコンパイルしても動かなかったので、バージョンの関係かなとさらっと流すことにした。
5章は食べログAPIを使ったアプリの開発なのでこれも楽しみ。
それから、function(){}とか()();とか毎回書くのもだるいので写経が終わったらCoffeeScriptで書くことにした。
@ando_ando_andoに呼ばれてコミュニティfでSphinxサイト構築の手伝いをしてきた。彼のためのGit入門サイトが出来てたのを本人に教えてもらったのだけど、alias切ってなくてstatusとかcommitとかフルで手打ちしてたので、上の4つくらいはやっておいたほうがいいんじゃないかなぁ(と今思った)。
ついでに、@ando_ando_andoの「静岡の東部にはHaskellerが多い」という主張を検証するために、今週末に香香飯店あたりで集まって飲むことになったので、参加される方がいれば連絡してください。
さて、彼はインフラエンジニアなので、作業メモとかblockdiagで描いた図なんかを手元で編集して、さくらのVPSで管理したいそうだ(GithubPagesでいいじゃんって言ったら、認証かけたいからそれはダメらしい)。

という状態にして、サーバー側にGitの共有リポジトリ置いて、プッシュしたタイミングで公開サイトのほうも更新するようにフックを設定しておけばいいよねーという僕の提案に対し
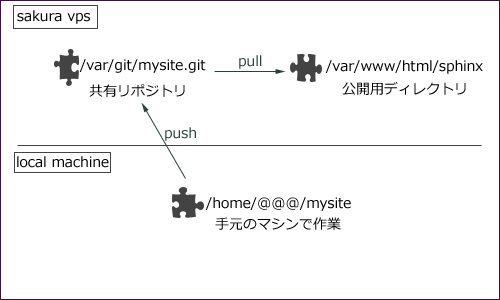
pushしたらpullするようにフックを設定すると、もとのrstとかMakefileがサイトのディレクトリに含まれてしまい美しくない。_build/html以下のファイルだけを公開サイトに置きたいと言い出した
ここから、ちょっとハマった。
_build/html以下のみを公開するんだったら、サーバー側にpushした後に、一回cloneとかpushして作業ディレクトリを作ってからcpするなりしないといけないということなので、最初からbareオプション付けないで共有リポジトリ設定すればいいんじゃないと。
これは見事に失敗する
remote: error: refusing to update checked out branch: refs/heads/master
remote: error: By default, updating the current branch in a non-bare repository
remote: error: is denied, because it will make the index and work tree inconsistent
remote: error: with what you pushed, and will require 'git reset --hard' to match
remote: error: the work tree to HEAD.
メッセージ見たら、まぁそうだよなと思った。なので、これは却下した。
結局サーバーにもクローンを作って_build/html/*を/var/www/html以下の適当なディレクトリにコピーするようにした(今ココ)。
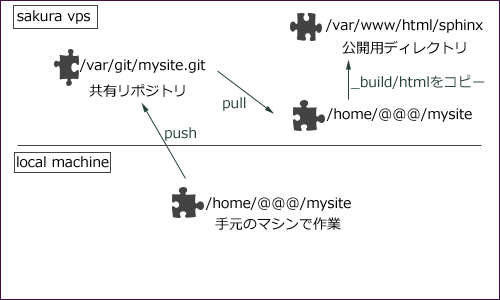
手でコマンド叩いたけど、フックに書いておけばいいかな。
単にbuildしたやつをscpすればいいんじゃない?ってことで
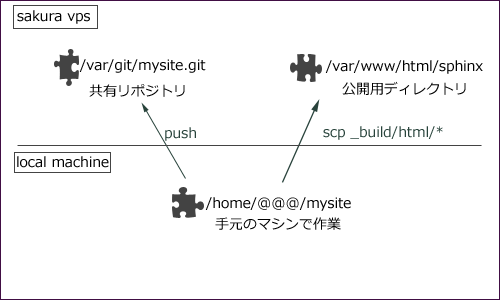
を提案してみたが、彼の美意識にそぐわなかったのかボツった。
cpするためだけにサーバー側に作業リポジトリを作っておくというのはなんとなく気持ち悪いんだけど、他にいい方法ないのかな?
Makefile書き換えて/var/www/htmlにbuildするようなオプション付けておけば、そもそも_buildをGitで管理しなくていいだろうとも思うんだけど、そこらへんの管理のさじ加減みたいなのもちょっと自信がない。
Pythonプロフェッショナルプログラミングになんかヒントっぽいもの書いてないかなぁと読みなおす。
2日目の途中で帰ってしまったので、朝コーヒーを飲みながら、残りのスライドを眺めてた。
HTMLテーマの拡張の話とDocutilsが参考になった。
そういえば二年くらい前に原稿書くときに使ったときはwordに出力するのに難儀したけど、今はdocxに出力できるらしいので、MSWORDな会社でも安心して使えますね。さらにmoin2を組み合わせれば、普段はWikiで使いつつ、必要に応じてSphinx経由で好きな書式で文書出力ってのもやりやすくなるだろうし。
21092012 life
パーマカルチャーには農業的な要素は外せないのかな?まぁ生きることは食べることなのでそうなんだろうが。
パーマカルチャーは、石油などの化石燃料に多くを依存する暮らしを改め、太陽の恵みを十分に活用して環境にやさしい循環型の社会を築くという思想です。
エッジ効果という考え方は面白かった。つまり異なる環境が接する縁に豊かな生態系が生成するということであるが、汽水とかをイメージするとわかりやすい。
それから小規模集約システムという考え方も参考になった。
20092012 Python SQLAlchemy
単にタグを含むエントリを取ってくる場合にはこうやればいいんだけど、さらに絞り込む場合にどうやればいいのか悩んだ。
filter(Entry.tags.in_(tags))
とかやったら、
"in_()" operator is not currently implemented for many-to-one-relations
みたいなエラーが出てきたので、グーグル先生にお伺いを立てたら解答が見つかった。
というわけで
Entry.query.filter_by(status=1).filter(Entry.tags.any(Tag.id.in_([tag.id])))
という感じで、anyとin_を組み合わせるのがいいらしい。
もう少し精進せなアカンなと。
結局こういったあたりで悩むんだったら、最初からpymongoでいいんじゃなかろうかと思ったりするんだけど、Flask-SQLAlchemyが便利すぎなのでなかなか悩ましいところ。
20092012 Python
Python Testing: Beginnerと同時期に買って一緒に読んだのだけど、書評を書いてなかったので今更ながら書いてみた。
Python Testing: BeginnerはユニットテストとかTDDの習得に主眼を置いているのに対し、本書はもうちょっと広くて高度な内容を取り扱っている。
BDDとか受け入れテストとか(Jenkinsを使った)継続的インテグレーションとかテストのカバレッジとかスモークテストなんか。
最終章の「良いテストの習慣」はなかなかいい言葉がまとまっている(ような気がする)
こんなかんじで12の習慣が。
個人的に良かったのがBDDの章であった。本書ではnose+mockitで説明されてた。ちなみに僕はpyVowsを使っています(Node.jsにVowsがあるので)。
それからlettuceの説明もよかった。これはちょっと試しただけで全然使ってないけど、そろそろ真面目につかうことになりそうだ。
というわけで、両方とも役に立っている。
19092012 Python
公開番号.pdfとかなってるんだろうから楽勝だろうなと思ったら、そんなことはなくてドキュメント用のIDがついていて面倒くささが20%増量してた。
検索してpdfのリンクをスクレイプしてダウンロードするようにしておいた。
こんな感じ
import sys import requests from pyquery import PyQuery as pq wipo_url = "http://patentscope.wipo.int/" def get_pdf_url(wipoid): url = wipo_url + "search/en/detail.jsf?docId=" \ + wipoid + "&recNum=1&tab=PCTDocuments" d = pq(requests.get(url).content) pdf_link = pq(d('table.rich-table:eq(1) a:contains("PDF")')[1]).attr('href') return wipo_url + pdf_link if _name_ == '__main__': wipoid = sys.argv[1] pdf_url = get_pdf_url(wipoid) with open(wipoid + ".pdf", "wb") as f: f.write(requests.get(pdf_url).content)
pyqueryがちょっと決め打ちしすぎなのと、requestsでgetしたのをファイル開いて書き出してるんだけどsaveみたいなメソッドないのかな?
18092012 work
付箋の数と良書度は比例する(脳内調べ)。
アジャイルとウォーターフォールという二元論的な考え方は、その概念が普及する段階では役に立ちましたが、もうその次代は終わりつつあると思います。様々な開発法があるなかで、どのようなプロセスで開発するか、具体的な実践技術が求められているでしょう。

僕のチケット駆動に対する期待は、創薬研究への応用なので、チケット駆動開発の背景にある考え方がぎっしり詰まった本書は、色々な発見や再発見があったり、今の仕事のアナロジーを見つけたりとかなり満足度の高い本だった。ただ、redmineをある程度使っているとか、アジャイルサムライ読んだとかそういいう基礎知識は必須なので、いきなり本書を読むよりは前作を読んだりしておいたほうがいいかなと思う。
本書は、ソフトウェアの使い方が載っているわけではない(mantisくらいかな)ので、そこは注意。
障害管理ツールの処理手順(p.24)を創薬探索系に重ねると、
という感じになるかな。そうすると障害とは何か?という話になるが、創薬系だと予想外の結果ということになるだろう。
予想外というのは仮説駆動開発の文脈だったら、なんのために合成するのか?という最初の目的が達成されたかどうかで判断するところだろうが、明確な目的を持って合成されることは少ないので、MMPに照らし合わせてcliffかどうかで判断してもいいかもしれない。結局cliffは予測外の事象だからね。
創薬系だとリポジトリにあたるものは既に存在するので、そこから今後の予測を行う技術は非常に興味がある。本書では詳しく解説されてないので、他の文献をあたろうと思った。
本書を読んでredmineのバージョンの使い方を理解した。だが、創薬系だと多次元で並行的に進めていくので、ソフトウェア開発だと2系と3系を同時に開発するみたいな感じかなあ。ちょっと難しい。
バージョンの概念は、単なるタグだけでなく、合意というマネジメント要素も含んでいるのです。
p.295のバージョンの概念が欠落する理由も参考になった。
著者の方からレスポンスを頂いた。ありがとうございます。
Q.創薬系のプロジェクトのバージョンとは何か? A.プロジェクトのマイルストーンに相当します。 学会で報告する、創薬研究の開発が完了する、などのチェックポイントが大きなマイルストーンになりますが、たぶん1ヶ月単位で意味ある成果物を出せるように、マイルストーンの目的を明確にすればいいでしょう。
大きいマイルストーンはあるのだけど、一ヶ月単位で測れるようなマイルストーンというのはあまり見ない気がする。というわけで、今必要なのはそういうブレークダウンした形のマイルストーンをどう定義するかだな。そういう意味ではメトリクスも足りてないだろう。
もう一つは、創薬開発手法は生産ではなく開発だという点において、トヨタ生産方式みたいな工場の生産系よりはソフト開発手法にすごく似ているのだけど、大きく異る点が1つある。 それは探索の割合が非常に大きいということだ(ライフサイエンス全般に言えることだけど)。これは工学と明らかに違って、コントロール出来ない要因を多分に含んでいて、それを考慮したような仮説ドリブンなマイルストンが必要なんだろうなぁと。
もう少し丁寧に考える必要があるが、理解が前進したので嬉しい。
 ストーリーでわかる! ブルー・オーシャン戦略実践入門
ストーリーでわかる! ブルー・オーシャン戦略実践入門 Titanium Mobileで開発するiPhone/Androidアプリ (Smart Mobile Developer)
Titanium Mobileで開発するiPhone/Androidアプリ (Smart Mobile Developer) Pythonプロフェッショナルプログラミング
Pythonプロフェッショナルプログラミング Gitポケットリファレンス
Gitポケットリファレンス エキスパートPythonプログラミング
エキスパートPythonプログラミング パーマカルチャー菜園入門
パーマカルチャー菜園入門 Essential Sqlalchemy
Essential Sqlalchemy Python Testing Cookbook
Python Testing Cookbook Python Testing: Beginner's Guide
Python Testing: Beginner's Guide Redmineによるタスクマネジメント実践技法
Redmineによるタスクマネジメント実践技法 アジャイルサムライ−達人開発者への道−
アジャイルサムライ−達人開発者への道− チケット駆動開発
チケット駆動開発