
15102017 chemoinformatics
無事に終了しました、参加されたみなさんお疲れ様でした。
今回話すのが忙しくて写真取ってない…
尚、12月には生命科学データ解析本の読書会が静岡で開催されるそうなので、興味のある方は参加すると良いかと思います。僕も行けたら行きます(懇親会は日本酒が美味しいお店になるという噂です)。
15102017 chemoinformatics
無事に終了しました、参加されたみなさんお疲れ様でした。
今回話すのが忙しくて写真取ってない…
尚、12月には生命科学データ解析本の読書会が静岡で開催されるそうなので、興味のある方は参加すると良いかと思います。僕も行けたら行きます(懇親会は日本酒が美味しいお店になるという噂です)。
07102017 東京
エリックサウスに始まりエリックサウスに終わるといった出張でした。
お昼はエリックサウスでビリヤニという定番の流れ。

夜はなにげに入った小池屋というホルモン屋さん。
ガツだったかな。あとはタン塩


左は忘れた、右はポテサラかな


厚揚げは美味しかった。

ゴヴィンタスで昼食。ココらへんはインド人が多いそうなので本場感あるレストランが多いそうです。 南インド的なランチを頂いたけど量が多かった。料理の写真はロストした。

山城屋酒場。結構前から気になっていて行ってみたところの一つ


ブツはまあまあ、天井にあるのは扇風機なのかな?


ナンコツの唐揚げ、ニラのおひたしはショウガのアクセントがよい。


豆アジの素揚げもカリッとしていて美味でした

帰りにまたエリックサウスに寄って軽くつまんだ。
インド版梅割りって感じ。梅干しの代わりにタマリンドで焼酎の代わりにヴォッカだった。 小洒落た感じで美味しかった。それからナスのアチャール最高


パパドは美味い、フィッシュアンドチップスもいけた


カリフラワーのスパイシー揚げ物(ゴビだっけ)は本当に美味しい。

今回は色々と行けてよかった
07102017 chemoinformatics
今までのみなさんのスライドが分散している状態なのもあれなのでMishima.sykのGitHubPageを用意しました。
歴代の料理写真をつけたりして華やかさを出せればよかったんだけどあまりjekyllも知らんので一通りまとめたら、やった感が出てしまった。
気になる人はリポジトリをいじってください。
 Working with Static Sites: Bringing the Power of Simplicity to Modern Sites
Working with Static Sites: Bringing the Power of Simplicity to Modern Sites01102017 pokemongo
昨晩タマゴからクヌギダマが孵化して、50km歩かずに飴が溜まった。

進化させてコンプ

あとはレベルをあげるかサニーゴ獲りにいくかという。あとは近所のジムを金色にするくらいかな。
30092017 pokemongo
やっとプテラが出た。長かった…w

カントーよりも先にジョウトがコンプしそうだった。あとクヌギダマ50km連れ回すだけなので一週間くらいかな。

これでサニーゴ狩りに台湾か沖縄に行く理由が出来た。台湾で美味しいもの食べたいから台湾に安く行ける方法を探し始めてる。
金のコイキングもやっと捕獲できたので赤ギャラドス作った。飴を投入するかどうかはわからない。
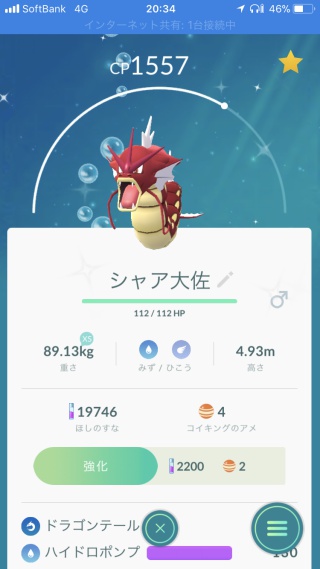
純正のバリヤード。横浜産なんてパチもんやで( ・`ω・´)
テーゲル空港で見かけたカブトムシ。欲しいなぁ…

30092017 Python
ここ2,3ヶ月python-amazon-product-apiが動かなくなっていて、仕様かなんか変わったのかなーなんて放置していたんだけど。
手元の開発環境ではあっさり動いたので、なんだかなーと原因追求したところ、さくらVPSのほうの時間がズレていた。
というオチ。
今は動くので、これからも精力的にアフィリエイトポチポチ貼りたいw
30092017 Python
買うかどうかは中身見てから決める。
27092017 pokemongo
9/11にLv35に到達していました。一ヶ月弱くらいかかった。
そこから2週間経つのにいまのところ50万XPしか稼いでないのでこれから頑張りたいところ。
それから個体値100%のスイクンもゲットしました。

図鑑コンプはクヌギダマ連れ回してるからフォレトスは時間の問題なんだけど、プテラがいまだに出ないんだよねー。
もしプテラ取れたらサニーゴ狩りに台湾行くわ☆
期せずしてフィンランドへ入国したわけだが、午前中は代替ルートの手続きとかホテルの処理とかなんだかんだで潰れてしまった。
あとキャッシュはテーゲルで使い切ってしまい10ユーロちょいしか残ってない状態でホテルに収容されたという。
もうひとつは、午前3時にヘルシンキに到着したから、航空会社から提示されたバウチャーが「朝食付きその日チェックアウト」っていうチケットだったんだけど。
成田便はどうせ無理だろうなぁと、まぁなんか嫌な予感しかしないよね。
と思いつつ、朝食は楽しみw


朝食ビュッフェではおばさんたちが情報交換をしていたが、ネットにアクセスできねーとかそんな感じだった。 尚朝食はカリカリのベーコンは美味しかったし。豆のトマト煮もよかったしパンも美味しかった。日本のパンは食べられないけどこっちは大丈夫、飽きない。
カウンターでホテルバウチャーをもらう際に、今後の代替フライトはネットでチェックしろという話だったので、資料作ったり、あれこれやったり、しながらフライトチェックしてたらやっと決まったっぽいのでとっととチェックインしたけど、内容を見たらこれって一泊しなきゃいけないじゃんという。お泊りの分と昼食夕食は自腹なんかねと思いつつ、一段落ついたのでビールを飲む。カルフっていうクマのロゴのやつ

グラスのビールを飲むのはこの出張で初めてで最後のもようw ドイツでは飲む時間と余裕がなかった。あと7ユーロは結構高いかな。
そして、これにより財布のキャッシュがコインのみの6ユーロ弱という…
仕方がないので近所のjumboに食料の調達に行くことにした(超楽しみw)
よくわからないけどフィンランド感はあります。


jumboはデカかったです。店と言うには巨大すぎる塊 って感じ。カップヌードルとかビールとか物色しつつ、チリコンカンの素とかパタの素とか完全に自分用おみやげを物色。
ちょっと余裕がなくてベルリンのスーパーは物色できなかったんだけど、ヘルシンキのスーパー(prism)は果物が色々あってそそられたのと、クノールが色々出していて見ているだけで楽しかっのと何故かスパイスが充実していた。
ビールは美味しい。IPAが特にいい感じ。SAIMAMAというレッドエールはいまいちだった。

ヌードル。日清のは焼きそばだと思うがフィンランド用にチューニングしてるのでそこを感じ取りたいw


これは自分用お土産。チリコンカン作る

時差ボケしたくないので早めに寝たいんだけど、現在いい感じの夕方なんだよねー。
あと自分にとって観光気分をそそられるのが、歴史的遺物を巡るんじゃなくて、地元のスーパーの品揃えを 確認するほうだというのがねーw
23092017 berlin
割と強硬な日程をくんだのとUGMが朝から遅くまで充実していたのでほとんど会場とホテルの往復がメインだった。
ビールもホテルの自販機のBECKSしか飲まなかった。

なので、夕飯はホテル近所つまりSteglitzのcurrywulstを食べていました。
最初に見つけたZur Bratpfanne
トマトソースが結構酸っぱかったけど美味しかった。カレー感はあまり感じなかった。


次の日はImbiss Haaseです。 頑固そうなおじいちゃんが一人でまわしてたけど平日だから?トマトソース甘め。



Zur Bratpfanneの向かいあたりに、行列のできているお店があったので覗いてみると、Cebo's Gemüsedönerというドネルケバブのお店だったので、迷わず注文。
これは本当に美味しかった。そして3.5ユーロ


それから朝食のパンも美味しかった。

余談だけど、都市計画的には自転車に関してはちゃんと車道の端が自転車用レーンになっていていいなぁと思いました。

富士市の歩道を塗り分けるというのは仕様的に全然駄目だなと歩行者の立場でも自転車の立場でも 思うのでああいう、おかしなことはよろしくないと思いました。歩道の一部を自転車に割り当てるのは 頭悪いとしか言いようがない。車道プリーズ
 Dr. Bonoの生命科学データ解析
Dr. Bonoの生命科学データ解析 Nintendo Pokemon Go Plus
Nintendo Pokemon Go Plus PythonユーザのためのJupyter[実践]入門
PythonユーザのためのJupyter[実践]入門