
13032010 Android
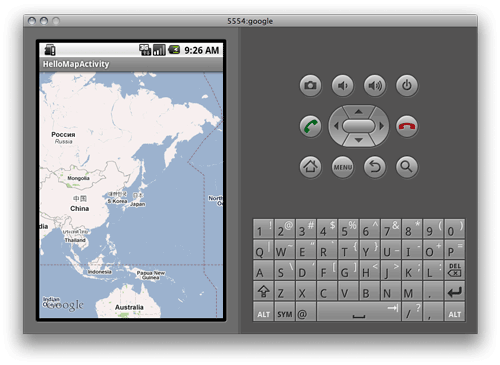
9章。build targetをGoogle APIにしないといけなかったのがわからなくて、MapActivity does not extend android.app.Activityとか、com.googleがimportできねーとか、マニフェストに謎のエラーが出たりして一昼夜悩んだ。
 Google Androidアプリケーション開発入門 画面作成からデバイス制御まで――基本機能の全容
Google Androidアプリケーション開発入門 画面作成からデバイス制御まで――基本機能の全容10章はバーコードリーダーにするサンプルなんだけど、実機ないと面白くなさそうだからいいや。
13032010 Android
9章。build targetをGoogle APIにしないといけなかったのがわからなくて、MapActivity does not extend android.app.Activityとか、com.googleがimportできねーとか、マニフェストに謎のエラーが出たりして一昼夜悩んだ。
10章はバーコードリーダーにするサンプルなんだけど、実機ないと面白くなさそうだからいいや。
12032010 music drum'n'bass
September (Camo & Krooked RMX)が素敵すぎる。
全体的にチャカチャカとウルサイけどまぁアリかな。
11032010 life
要するに複利にこつこつ投資しなさいというビギナー向けの内容
アセットアロケーションはしなきゃなと常々思うのだけどやってないのだよな。
最近の娘のブームが僕のmacbookでタブレット使ってお絵かきすることなので、僕は隣でビジネス本を読むことが増えている。
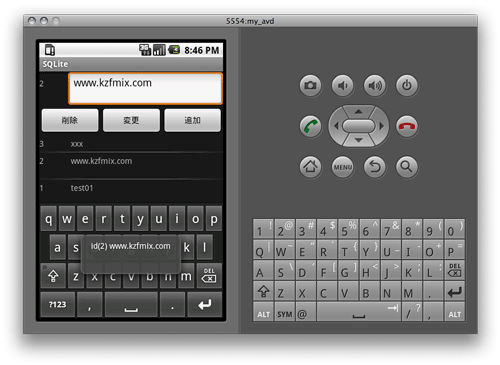
Google Android アプリケーション開発入門8章のSQLiteを使うサンプル
10032010 chemoinformatics Python network matplotlib
ふと、つぶやいた。
例えば
その時知りたいことは、
あたり。
現実の系に近づけるために、親化合物にはポテンシャルがあって、近傍探索すると、ポテンシャルの近くで活性が変化するモデル。あと同じライン(ブランチ)を継続して合成すると、ポテンシャル曲線が底に近づくのと、合成もSARに関する知識がついてくるので、活性は上がりやすくなって、かつ変動幅も小さくなるようにweightはだんだん小さくなるようにしてみた。
#!/usr/bin/env python
# -*- encoding:utf-8 -*-
# kzfm <kerolinq@gmail.com>
from random import random
import networkx as nx
import matplotlib.pyplot as plt
class Branch(object):
"""LeadOptimization flow"""
count = 0
@classmethod
def inc_count(cls):
cls.count = cls.count + 1
return cls.count
@classmethod
def get_count(cls): return cls.count
def __cmp__(self, other):
return cmp(self.act, other.act)
def __init__(self,potency,weight):
self.num = Branch.inc_count()
self.potency = potency
self.weight = weight
self.act = self.potency + self.weight * random()
def make_child(self,num_childs,potency,weight):
return [Branch(self.potency + self.weight * random(),self.weight * 0.7) for i in range(num_childs)]
if __name__ == "__main__":
max_comps = 500
initial_branches = 3
nodesize = []
nrange = []
erange = []
generation = 1
heads = [Branch(0.3,1) for i in range(initial_branches)]
G=nx.Graph()
for h in heads:
nodesize.append(h.act * 30)
nrange.append(generation)
while Branch.get_count() < max_comps:
new_heads = []
generation += 1
for branch in heads[:10]:
for new_comp in branch.make_child(int(5+20*random()),branch.potency,branch.weight):
nodesize.append(new_comp.act * 30)
nrange.append(generation)
erange.append(generation)
G.add_edge(branch.num,new_comp.num)
if new_comp.act > 0.75:
new_heads.append(new_comp)
heads = new_heads
heads.sort()
nx.draw_spring(G, node_size=nodesize, node_color=nrange, edge_color=erange,alpha=0.7, \
cmap=plt.cm.hot, edge_cmap=plt.cm.hot, with_labels=False)
plt.savefig("proj.png")
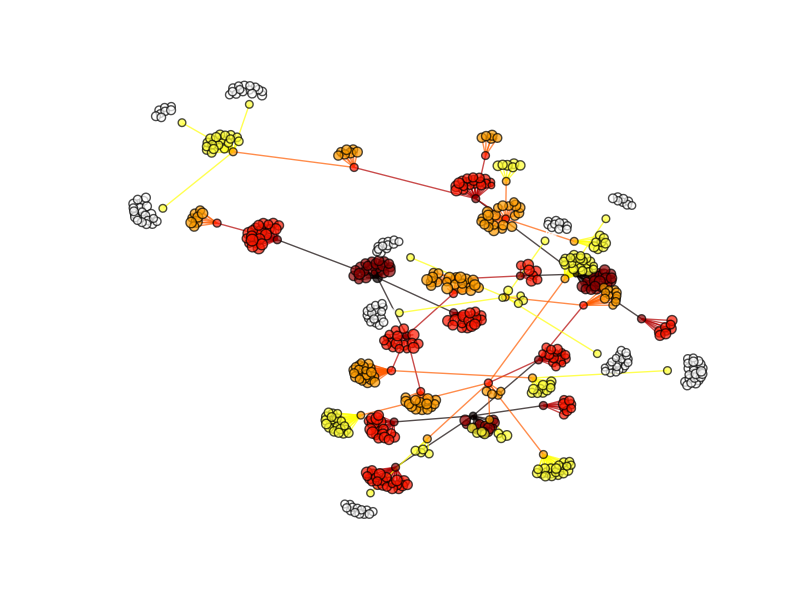
んーなんかいまいち。一応活性の強弱にあわせてノードのサイズが変わるようにしてみたんだけど、大きさがわからん。
09032010 Python machinelearning
Unsupervised Learning。なかなか面白かった。
 Machine Learning: An Algorithmic Perspective (Chapman & Hall/Crc Machine Learning & Patrtern Recognition)
Machine Learning: An Algorithmic Perspective (Chapman & Hall/Crc Machine Learning & Patrtern Recognition)K-meansの話から入って、K-Meansは一層のニューラルネットで表現することが出来ることを示していく。ニューラルネットで表現されたK-Meansはオンライン更新できるので、入力を一度に読み込まなくて良い(はず)。
そのあとSOMだったけど、SOMは知ってるので流した。
生態学のデータ解析 - GLMM 参照からたどれる数学セミナー2007が非常にわかりやすかった。
> library(glmmML)
> d <- read.csv("http://hosho.ees.hokudai.ac.jp/~kubo/ce/memo/hierarchical2007/figSS/d.csv")
> glmmML(cbind(y,10-y) ~ 1, data=d, family=binomial, cluster=d$plant.ID)
Call: glmmML(formula = cbind(y, 10 - y) ~ 1, family = binomial, data = d, cluster = d$plant.ID)
coef se(coef) z Pr(>|z|)
(Intercept) -0.03582 0.1578 -0.2270 0.82
Scale parameter in mixing distribution: 1.373 gaussian
Std. Error: 0.1389
Residual deviance: 259.7 on 98 degrees of freedom AIC: 263.7
 Mixed-Effects Models in S and S-PLUS (Statistics and Computing)
Mixed-Effects Models in S and S-PLUS (Statistics and Computing)この本の5,6章も何度か読み直さないとイケナイ。
働き方に関して。サステナビリティって言葉が頭をよぎった。
 小さなチーム、大きな仕事―37シグナルズ成功の法則 (ハヤカワ新書juice)
小さなチーム、大きな仕事―37シグナルズ成功の法則 (ハヤカワ新書juice)会社は大きいほうがいいなんて幻想だ。今日では誰でも自分のアイデアをもとにビジネスを始められる。高価な広告枠、営業部隊、オフィス、いや、会議も事業計画もいらない。昼間の仕事をしながら、初めは週末の数時間を費やすだけで十分だ。小さな所帯で、シンプルに、迅速に、臨機応変に—それで僕らは成功している。二つの大陸に散らばった十数人のメンバーだけで数百万人のクライアントを抱えるソフトウェア会社37シグナルズは、その優れた製品だけでなく、常識破りな会社運営法でも、業界観測筋の目を釘付けにしている。その創業者とカリスマ開発者が、いまのビジネスに真に必要な考え方を示す。
08032010 Android
6章のパズルゲームのサンプルを写経した。結構楽しい。
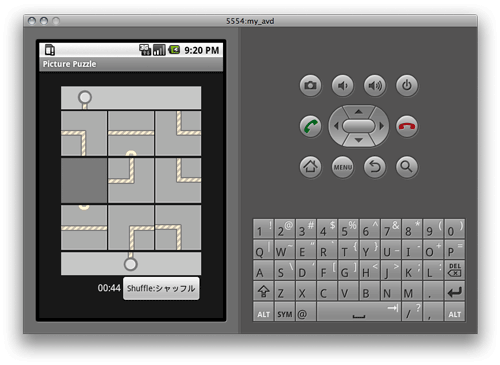
ソフトバンクのAndroid端末早くでないかな。
08032010 life
なんとか合格したっぽい。今回難易度高めっぽいのでかなりラッキー感満載。次回は難易度低くなりそうな予感がするので、このまま2級もいっとこかなーと思ったりするんだけど、時間がとられるからなぁ、、、悩む。
使った問題集は主に下のやつ。ただ、いきなりこれをやって挫折しかけたので、ブックオフでもっと簡単なやつを105円で買ってきて解いた。
基本は、本に直接書く。どうせ何度も繰り返しやらないし、間違ったところに赤で印つけておけば、二回目流し読みしたときに思い出すし、どうせ受かったら捨てることになるんだから綺麗に使う必要もない。
あとは、わかりやすい簿記でも読んでおけばOK
仕分けは
を押さえる。
問題は1,2,4,5,3の順に解いた。3はT字で解けるようにしといたほうが楽。 最初にTをひたすら書いて、貸方借方に金額入れてった。そうしないと終わらん。
消耗品と消耗品費の違いを覚えて、棚卸の意義が理解出来るようになった。今まで、メンドクセーなとか思ってたけど。
 ABOVE & BEYOND
ABOVE & BEYOND 「しくみ」マネー術
「しくみ」マネー術 Wacom Bamboo Fun CTE-450/W0
Wacom Bamboo Fun CTE-450/W0 パターン認識と機械学習 下 - ベイズ理論による統計的予測
パターン認識と機械学習 下 - ベイズ理論による統計的予測 計算統計 2 マルコフ連鎖モンテカルロ法とその周辺 (統計科学のフロンティア)
計算統計 2 マルコフ連鎖モンテカルロ法とその周辺 (統計科学のフロンティア) 母集団薬物データの解析 (統計科学選書)
母集団薬物データの解析 (統計科学選書) 日商簿記3級240%完全合格自習問題集 新訂第1版 1人で勉強して1回の受験で合格する (とりい書房の負けてたまるかシリーズ)
日商簿記3級240%完全合格自習問題集 新訂第1版 1人で勉強して1回の受験で合格する (とりい書房の負けてたまるかシリーズ)