
11022018 life
二年前の6月(2016.6)に虫垂炎になってから抗生物質でなんとかしていたのだけど、(2017.1),(2017.12)そして先週と、だんだん頻度が高くなってきていて流石にめんどくさくなったので切り取ってもらうことにした。
月曜の深夜にひどく傷んだので、火曜日に会社を休んで診察->そのまま入院、次の日(水曜日)手術(開腹手術)をして、だらっと過ごして土曜の朝に退院という流れ。
尚、歩くとお腹が痛いけど、チャリだと負担が少ないのでチャリでぐるぐるとポケモンイベントを堪能出来ましたw今は動きが鈍い以外はいつもの生活と変わらない感じ。
一応入院中のアクティビティをメモっておく
2018.02.06 (Tue)
早朝から虫垂炎の痛みで眠れず、会社を休んで病院直行。先生に「流石に切りますかね?」「はい、喜んで!」って感じ。一旦帰って荷物(パソコン関連w)を準備して入院。前日は元気なのでmmpdbのSQLAlchemy化をやって捗ったw
前日に手術の準備として、
- 陰毛を剃る
- おヘソ周りクリナップクリンミセス
が行われました。1は思ったよりも剃られるわけではなくてなんというか競泳用海パンのあたりまででした(知らんけど)。問題は2のほうで、おヘソを若い女性の看護師さんにオリーブオイル付きの綿棒でクリクリされるので、ヘソが汚いと更なる何かが待っている感じでした。僕は特に問題なくクリアーしたのでわからんけど、腹部の手術を受ける際にはヘソ周りの綺麗さは重要なファクターのようなので気をつけましょう。
2018.02.07 (Wen)
手術時間は午後って伝えられていたんだけど、正確な時間は決まっていなくて、午前中は論文読んだり、コード書いたりして時間を潰していた。手術自体には不安はなくて「どうせ切っても、たかだか虫垂炎のクソ痛い時と同程度なんでしょ?」って感じ。むしろ尿道カテーテルですよ、奥さんって感じで、ググるとすごい痛いとかいうレポばかりで不安としては9割方そっちだった。女性のカウンセラーに「何か不安なことはないですか?」と言われて、真っ先にそのこと訪ねたら「私女なので(失笑)」みたいなw テンパってたw
手術は1500からで手術台に載せられて、酸素マスクを当てられて麻酔薬を少しずつ流しますからねって言われてから、本気で目を開けていたんだけど、気づいたら起こされていて手術が終わっているパターンだった。この間1時間くらいだと思う。尿道カテーテルが装備されていて、起きる事前に座薬(鎮痛剤)が打ち込まれていたけど、尿道カテーテルの違和感はなかった。それよりもお腹が痛かった。流石に術後はぐったりしていたらしい。
その日の夜は基本的にお腹が痛いのと背中と腰が痛くて寝られなかったのだけど、鎮痛剤は座薬と筋注を交互に打つルールになっているらしく、経験では座薬の鎮痛剤は内臓の痛みとか腰痛を和らげる効果はなく辛かった。筋注は完全に痛みが遮断して数時間の睡眠を堪能できた感じ。鎮痛剤はTPOにあわせて使い分けられたほうがいいので、painのプロジェクト頑張ろうと思いました。あとこの論文反芻していた気がする。
2018.02.08 (Thu)
結局、夜中からほとんど寝られず朝を迎えた。朝、尿道カテーテルを外すことになり、痛さにドキドキしたが、ほとんど痛みはなく終了。カテーテル自体そんなに違和感がなくて(痛みのほうが勝っていた)胃カメラの内視鏡検査のほうが辛かったくらい。その後にトイレに行って排尿した時に、空気の入ったホースみたいにゴボゴボ鳴るのが面白かったw 膀胱に空気を入れるような薬があればゴボゴボプレイが出来て良いかもと思った。
カテーテル抜いて、部屋に戻ったときにはぐったりしていて、今日は終わったわと思ったけど、一眠りしたら元気になったので午後からはコード書いたり論文読み始めていた。大部屋から個室に移してもらったので、のびのびと色々やれて良かった。入院したら個室がおすすめ。

2018.02.09 (Fri)
なんもやることがなくて、ネットのチェックしたりコード書いたり、論文読んだりしていた。傷がちょっと痛くて、腹筋を使う動作が辛かったが、普通に集中して色々とこなしていた。ポケモンのジムとかポケストップが周りにないので悶々したけど。暇そうにしていたら次の日に退院の許可が出た。
2018.02.10 (Sat)
1000くらいに退院できた。もう少し長引くかなと思っていたので開腹手術にしては早い退院だったのかと思う。腹膜炎併発したら一ヶ月近く入院するらしいから早めに受信して、薬で何とかするなり切るなりしたほうがいいなと思いました。
帰ってきてからゆっくり観察してみた。医療用ホッチキスで留めてあるので、抜糸というよりはバッチキスと言ったほうがよいのではなかろうか?
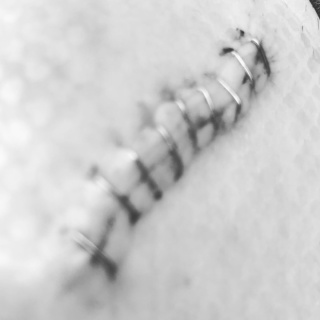
以上、初めての入院と手術。
 深層学習
深層学習 プログラマの数学 第2版
プログラマの数学 第2版 プログラマの数学第2版
プログラマの数学第2版 木村の矢倉 急戦・森下システム
木村の矢倉 急戦・森下システム 木村の矢倉 3七銀戦法基礎編
木村の矢倉 3七銀戦法基礎編












 速習 強化学習 ―基礎理論とアルゴリズム―
速習 強化学習 ―基礎理論とアルゴリズム― 詳解 ディープラーニング TensorFlow・Kerasによる時系列データ処理
詳解 ディープラーニング TensorFlow・Kerasによる時系列データ処理