
31122019 bioinformatics
DNAの章
 細胞の分子生物学
細胞の分子生物学ヒストンコード仮説とATAC-seqが面白いかなと。
31122019 bioinformatics
30122019 bioinformatics
タンパク質の章
生物学の説明一般に言えるんだけど、抽象的すぎてよくわからんことが多い。
例えばリン酸基についても2章で述べられているように水溶液中ではイオン結合や水素結合力って急激に減衰するはずなのに、リン酸基が溶媒側の残基に付加することでコンフォメーション変化が起こるとかそういう説明に持っていくのに違和感がある。「リン酸基は2価の陰イオンだから違うんやで」っていう理屈でもいいんだけど、その場合はどのくらいのエネルギー変化が期待できるとかそういう説明ほしかった。
あとちょっとの変化がとか書いてあるけど、ダイナミズムに対してどうなんかな?という疑問はつきまとってしまう。

LYSとメチル化が相性いいのはここで理解したからいいけど、アセチル化ってどういうエネルギー成分が支配的になってくるのか興味がある。
構造探すか。
29122019 bioinformatics
生物はどれも化学反応系にすぎない
化学反応の章だったのでほぼ理解していた。さくさく読み進んだ。
これの出典が知りたかったがわからなかった。FMOのES項をどれくらい補正すればいいのか知りたかったのだが

28122019 chemoinformatics
This is the 24th article of the Drug Discovery Advent Calendar (Dry) 2019.
I was very impressed by the weak hydrogen bonds in the article, A C-H···O Interaction Against IRAK4 / Drug Hunter . So I checked that interaction with Fragment Orbital Method
PDB:6UYA was used as a complex structure and details of calculation are here
If you are not familiar with FMO, this book will help you.
 Fragment Molecular Obital Method : Practical Applications To Large Molecular Systems [Hardcover] [Jan 01, 2009] Fedorov
Fragment Molecular Obital Method : Practical Applications To Large Molecular Systems [Hardcover] [Jan 01, 2009] FedorovThis is actually the article for the 24th advent calendar, but I can't give you this book because I'm not Santa Claus. If you click on the link instead, I'm sure that Amazon will deliver this book to you instead of Santa Claus.
What a wonderful Christmas gift it is! Now, click it!
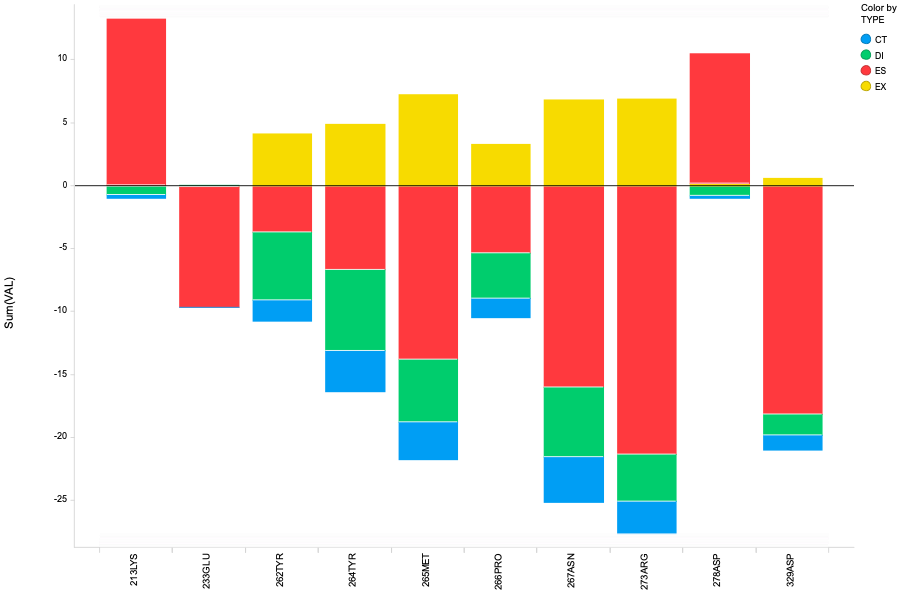
The result is here. I only show the interaction which have strong stable/unstable interactions for clarify.
The result shows that there is a C-H···O Interaction between compound and protein(TYR264 in this case), but the interaction energy is rather weaker than the typical hydrogen bond.
*** The amino acid number and fragment number doesn't exactly match in FMO. The carboxylic acid moves to the next residue because of cleaverage in protein at C (sp3) -C (sp3) bond.
And also I'm not sure that the nature of this interaction is same as hydrogen bond. I guess it also includes side chain effects because DI term is slightly large. To clarify this, we can replace TYR with Gly and execute FMO calculation again.
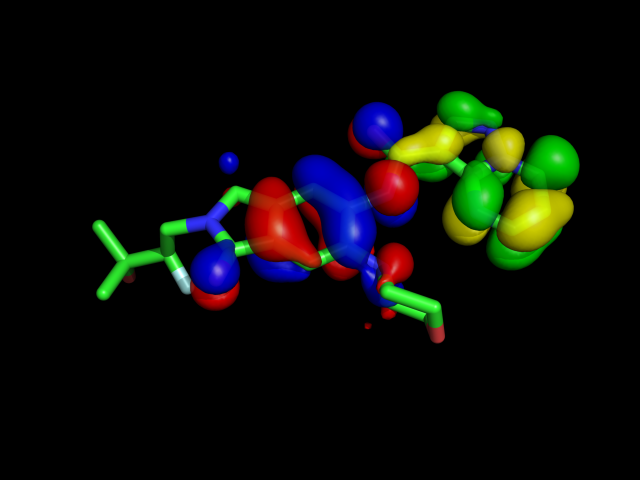
Next, we will interpret it by frontier orbital, but it's WIP.
I guess we'll know a lot if I do it so far, but I've run out.
Have a happy new year!
28122019 life
11月の後半から12月の中旬までずっと学会に入り浸っていて、久しぶりの朝の富士山は雪の侵食がそうとう進行していた。

Repubrewに行ったら新たなビールが揃っていた。左の濁っているのがホップを過去最高に投入したHazyIPAだったと思う。右は忘れた。


その後忘年会が続き、二次会で豪快な肉を食べていた。若いっていいなと思いました。ちなみに学会出張と忘年会のコンボでやたらと身体が重くなったので年末は運動をしなければならない。

年末読書用の細胞の分子生物学も届いた。

先週土曜日に華味に昼を食べに行きつつ新年会の予約してきた。それまでずっと予約の電話をしてたんだけど、全然つながらないので、直接行ったほうがいいかなと。
頼んだのはラム焼き肉だが選択をミスった。美味しすぎて食べ過ぎたのがミス。ご飯おかわりしてしまったわ。

その後、昼ビール

日曜はずっと行きたいと思っていたヤシオスタンに行ってみた。
カラチの空まで歩いて20分。ポケストップもないから退屈です。連れ回してるランターンを撮ったらドーブル写り込んでた。

カラチの空ではビリヤニ


マトンのカレーとロティ。多人数で行ったほうが種類も楽しめて良い感じでした。色々注文したいものがあったのでまた行きたい。


知り合いのインド人に「ヤシオスタン行ったで」ってメールしたら「埼玉に住んでたけど、そんなん知らんかったわ。今度チェックするわ」と返事が来た。
27122019 life
3月のライオン 15
できないには
の2種類がある。
21122019 bioinformatics
細胞の分子生物学を書い直した。最新版の必要性は特に感じないので、コスパの良い第5版の中古にした。
昔は第3版を買って勉強したように思う、といっても流し読みだったが。
15122019 chemoinformatics
この記事は、創薬 (dry) Advent Calendar 2019 の14日目の記事です。
先日とある学会で@torusengokuのDNAメチル化のポスターを聞いていたら、横からある助教の人が乱入してきて「メチル基とアミノ酸残基の相互作用がこんなに強いのは納得いかない」といようなことを言い出してディスカッションになった気がします。結局これはカチオン-πであろうということで終結したのだけど、この議論を通して、
という重要な知見を得ることができました。ついでに@torusengokuからMeCP2も同じような結合様式を取っているようだと教えてもらったので、計算してみたというのがこのエントリーになります。
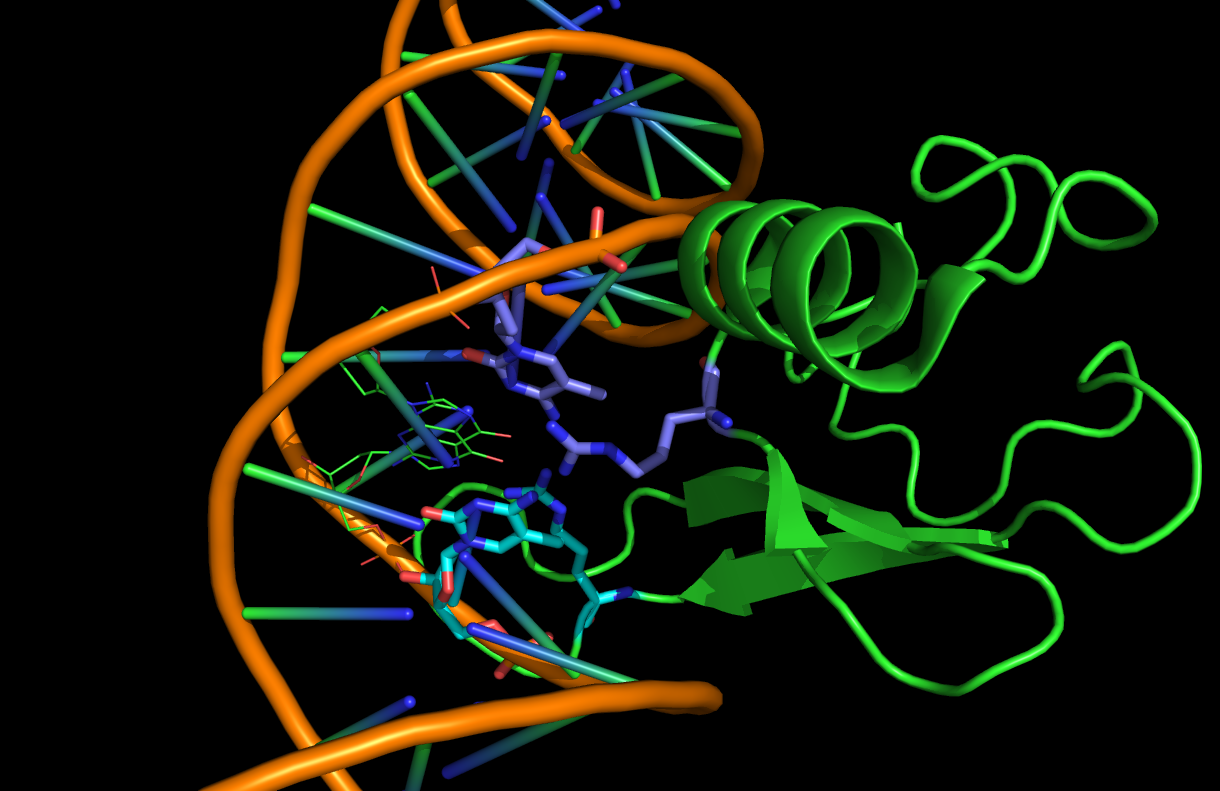
MeCP2はmethyl-CpG binding protein 2であり、methyl-CpGを特異的に認識して結合するタンパク質です。結晶構造からはMeCPのARGがメチル化されたCの対のGと結合しています。この相互作用は相補鎖についても同様です。
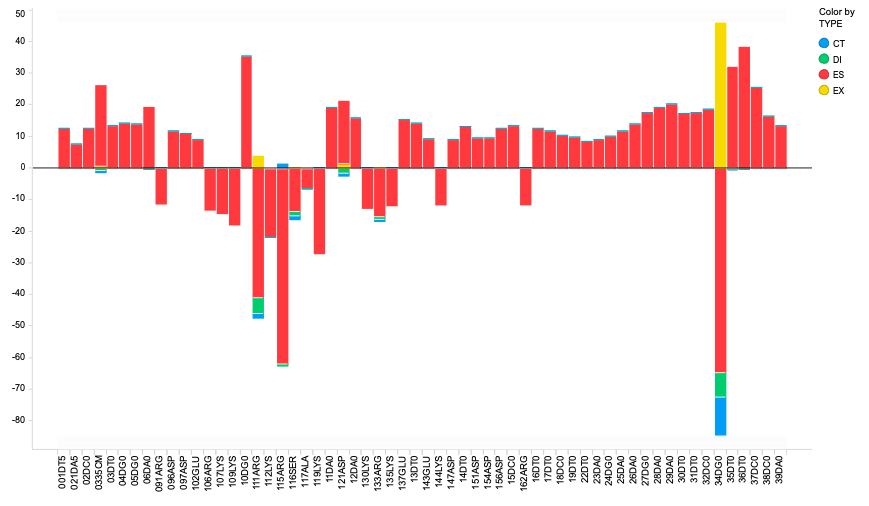
FMO計算をしてメチル化CのPIEDAを見てみると、ES項がごちゃごちゃと現れてきますが、実際の溶液中だとほとんどキャンセリングしてると考えられます。このあたり改善していく必要があると思いますが、どうすればいいのかわからない。
ESを除いて見やすくすると、対となっているGとの相互作用が強く出ていますが、それと同時にARGとのDIの相互作用もかなり強く出ています。これはカチオン-π相互作用でしょう。
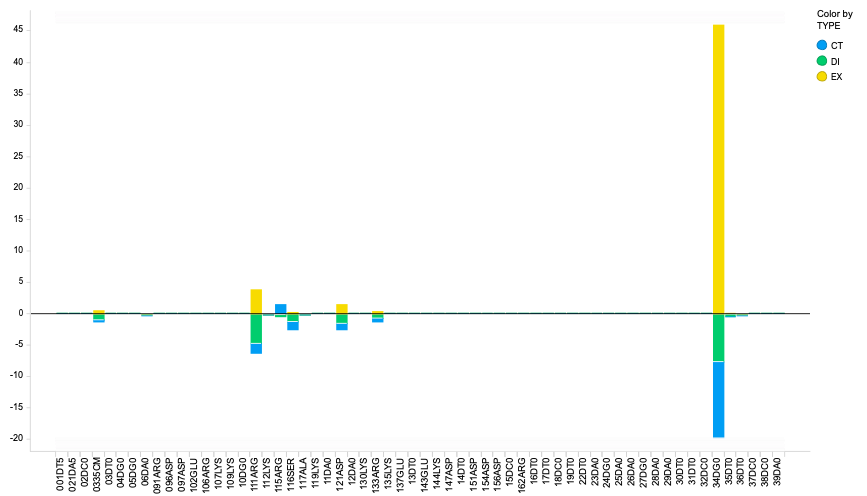
このあとは脱メチル化したモデルを作ってPIEDAの差分を取ったりするとメチル化の効果によりどのくらい結合が安定化したかとか成分がどう変化したかとかの詳細がわかります。
このような、protein-DNA interactionやprotein-protein interactionに関する理解を深めておけば、従来のkey-lock型の相互作用に基づかない新たな生体干渉方法のアイデアが浮かぶんじゃないかなーと思います。
先週の分生の相分離のワークショップ出たときも、「相分離はエンタルピードリブンだ!」とおっしゃっていたので、構造生物学から攻めることできちんと理解される生命現象は少なくないのではないかと考えています。
14122019 chemoinformatics
なにげに構造活性相関シンポジウムは初めてです。依頼講演で呼ばれたついでにポスター発表しようと思ったらオーラルに変更されたので、2演題話してきました。両方とも活発な質疑ができたので、少しは盛り上げられたかな?と思いました。
構造活性相関シンポジウムって創農薬寄りなんですね。藤田センセだからまぁそうなんだろうなとは思いましたが。全体的に参加者の人達はMachine Learningをもうちょっとしっかり理解しておいたほうがよいのではないかな?と感じました。個人的にはMol2Vecの面白い使い方を知れてよかったのと私のにわか量子化学力をシャキッとさせるコネクションができて満足した学会でした。
あと、ポスターにOCamlのロゴを印字している方がいてOcaml愛に溢れとるなーと感じた。
私もHaskellでコード書いてポスターにロゴをのっけたいところ
前泊入りしたので羽田空港にて。静岡のHaskellerの嗜み。

熊本についたら、なんかイベントやってた。

夜はライフイズジャーニーっていうお店で熊本ラーメン食べた。

つまむものがないので、ラーメンをつまみに焼酎飲むらしい。まわりがそんな感じだったので 私もそれに倣った


帰りにくまモンラベルの白岳を買った

学会会場は熊本城の近くだったので、ちょっと早めに到着して散策(ポケストップを回す)してみた。


懇親会では日本酒飲めたので満足。あと色々お話したり議論できてよかったです。トレーナーのフレンドも増えたw

次の日も発表なので二次会に出ずにホテルに戻ったけど、お腹が空いたのでラーメン注入。 ここはまぁまぁかな。


二日目のランチは、前職で一緒に仕事をしていた方とラーメン。天外天行ったら夜のみ営業だったので黒亭。 生卵は入れず。


学会終了しても終電に間に合わないのでもう一泊して馬った。


馬ホルモン焼きとホルモンのポン酢和え。


馬刺しは別に興味なかったのでこんな感じ。御殿場でいつでも買えるしね。

最後にまたライフイズジャーニーに寄った。美味しいね、ここ。

今回は博多ラーメンを注文。こっちのほうが好きかな。


13122019 bioinformatics
兼務しているほうのユニットで忘年会があった。兼務になってそろそろ一年なんで今年は早かったなーと感じた。 bioinformatics関連でも来年はなにか面白い仕事をして学会発表したいですね。
真鯛のカルパッチョ

真鯛のしゃぶしゃぶ

真鯛の唐揚げ

鯛茶漬け

 3月のライオン 15 (ヤングアニマルコミックス)
3月のライオン 15 (ヤングアニマルコミックス)