
08122019 life
ブラックフライデーで安いヘッドフォン買ったのでたまにはお家DJしたい
08122019 chemoinformatics
この記事は、創薬 (dry) Advent Calendar 2019 の8日目の記事です。
皆さん料理は好きですか?レシピをいくつ覚えていますか? 食材や調味料が足りなかった場合にあなたはそれらレシピをアレンジすることができますか? もしアレンジできないのであれば、そもそも料理というものを理解していない証拠なので「料理の四面体」を読みましょう。
読んでいない人のためにネタバレを用意したので、ざっと読んでみてください。ちなみに私の強烈なaha体験はアヒージョと茹でた肉や野菜の油がけは可換であるという事実でした。これによりメタレシピというものに目覚めたし、急激に料理の応用の幅が広がった気がします。
さて、ここからが本番です。
みなさんはモダリティをご存知でしょうか? もし知らなければNew Modalities, Technologies, and Partnerships in Probe and Lead Generationが参考になると思います。
以下は全文にアクセスできますが、論調が私の主張と合わない部分があるので参考として載せておきます。
モダリティの話が出てくると文脈には「低分子はオワコン、これからは中分子の時代」という既存の手法との対立が含まれていたり、百貨店よろしく、いくつのモダリティをピラーにするかという風に語られることが多いように思いますがもう少し統一的な視点を与えられないかというのが今回のお話です。
そこで冒頭の料理の四面体の枠組みを借りてきて、それぞれの辺に「分子量」「MoA」「測定系」というパラメータをアサインします。するとそれぞれの辺を頂点に持つ三角形が(広義の)モダリティを形成することになります。
分子量に関してはよいし、MoAもセントラル・ドグマだと考えればOKかなと思いますが、測定系が連続値をとるというのはちょっと乱暴だけど無視してください。
これでキレイに抽象化できたかなと。
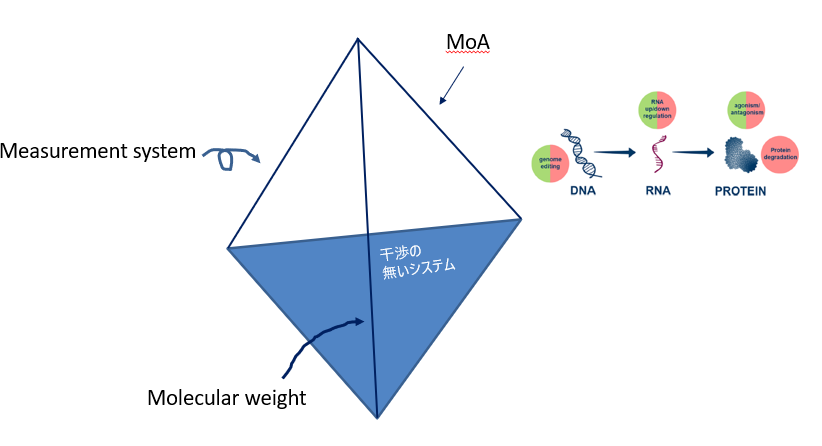
こうしてみる特にモダリティで組織化する場合にはそれぞれのモダリティに応じたテーマの探索を志向すると思うのでプロダクトアウト色が強くなりがちだと思うのですが、そのあたりどういう風に舵を取るんでしょうね? 個人的にはRight Target -> Right Modalityをどう選ぶかというMoA in(マーケットイン)なアプローチは重要なんじゃないかなーと思います。そしてそれができるのがDryの人達ではないかなと考えています。
結局モダリティで組織化せざるを得ないのは技術ロックされるからだけど、コンピューターサイエンスとしては低分子の構造最適化も、ペプチドの最適化に特に壁はないし、バイオインフォマティクスもやればいいので、別にプロダクトアウトの立場になる必要性もないでしょう。むしろRight Targetが得られたあとに適切なモダリティの選択とドラッグデザインができれば楽しくプロジェクトに関われてハッピーなんじゃないかなと。
ただそのためには、key-lockシステムを超えたMoA干渉のアプローチ方法を理解しておく必要があるかなぁと思います。さらには新しいWetの技術などもキャッチアップしないといけないけど、分子設計者としての幅は広がって楽しいでしょう。
今回昔書いた以下のエントリを参考に書き直してみました。
07122019 bioinformatics
07122019 chemoinformatics bioinformatics
朝は粥

分子生物学会というなのお食事会も最終日

昼は海鳴でラーメン。たしかにここは美味しかった。博多滞在中結局2杯しか食べられなかったので 今度はラーメン詣でにいこうかな。

デイトスの酒屋の角打ちでスタバったら当たりをひいて一杯サービスになった。


このまま帰るとただ酒になってしまうので、みやざきのひでじビールを頂いた。

新幹線の中では先程の酒屋で購入した三井の寿をちまちまやった。新幹線で飲まないと立派なHaskellerにはなれない。 すくなくとも静岡では一人前のHaskellerとしては認められない。

05122019 chemoinformatics bioinformatics 博多
05122019 chemoinformatics bioinformatics 博多
04122019 chemoinformatics bioinformatics
この記事は、創薬 (dry) Advent Calendar 2019 の4日目の記事です。
分生に来ていますが図書コーナーのbono関連図書のモテ期襲来が圧巻でした。
chemoinformaticsなみなさんもこれを期に購入してbioinformaticsも勉強しましょう。これからは両方できてなんぼですよ。
ところで、標題の通り我々(@iwatobipenと私)はpy4chemoinformaticsを書きました。そのきっかけがちょうど去年の分生で、ある出版社の方につないでもらいchemoinformaticsの書籍を検討してもらう機会をいただいたのですがボツになってしまいました。その際に目次を書いて提出したのですが、まぁ折角章立てしたんだしGitHubに残そうぜってことになった次第です。
私としてはMishima.sykとしてなんとなく何かを残しておきたかったのと謝辞を書きたかったというのが主なモチベーションですが、そのために共著になってくれた@iwatobipenをはじめ表紙を飾ってくれた@souyakuchan、誤字脱字の訂正を丁寧にしていただいた@antiplastics, @bonohu, @ReLuTropy, @ski_nanko, @torusengoku, @yamasaKit_には大変感謝しております。もちろん、学会などでお会いしたときに直接フィードバットしていただいた方のコメントもとてもありがたく感じています。
ちなみに、GitHubで本を書くのは結構簡単です。知らないといけないのは基本的なGitHubの使い方とasciidocの記法だけです。なぜmarkdownでなくasciidocを使うのかは、こっちのほうが、注釈つけたりするや表を書くのが簡単だからです。HTMLのレンダリングはGitHubのほうでよろしくやってくれますし、pdf化もasciidoctor-pdfでサクッとできます。もし、章には入ってないけどこれが入っていたら初学者は喜ぶだろうなとか、もうちょい高度な内容を章として追加したいなと思ったら気軽にPRしてください。わたしも、そろそろなんか追加しようかなと考えています。
今回表紙が創薬ちゃんなので、急遽駄文をアドベントカレンダーにねじ込むことにしてみましたが、私からのtakeawayは 「自分の属するコミュニティを大切にしよう、そしてそれ以外のコミュニティも同じくらいリスペクトしよう」 です。弱い紐帯の強さは異分野をリスペクトしてこそです。特にDryでやる人は自分の活躍分野を広げるためには現在関与している分野に精通する一方で新たな応用分野を探索する必要があります。そして自分の知らないWetの分野はブルーオーシャンになある可能性があるということは忘れないようにするといいと思います。
それでは今日も食の祭典「分生」を楽しみマッスル。
 【Amazon.co.jp限定】ダンベル何キロ持てる? Vol.1 (早期予約特典: アニメ特製プロテインシェイカー付) (全巻購入特典: アニメ描き下ろしイラスト使用全巻収納BOX) [Blu-ray]
【Amazon.co.jp限定】ダンベル何キロ持てる? Vol.1 (早期予約特典: アニメ特製プロテインシェイカー付) (全巻購入特典: アニメ描き下ろしイラスト使用全巻収納BOX) [Blu-ray]03122019 chemoinformatics bioinformatics 博多
食の祭典「分生」に来ています。
前泊の夜はshinshinでラーメン。あまり調子が良くなかったので、そのまま就寝

朝は軽く粥をいただく。ほんと朝は毎日粥でいいわってくらい粥が好き。間違いない。


ランチョン並ぶのも嫌なので、タマゴの孵化も兼ねて、呉服町駅近くの「みやけうどん」まで歩く。 博多のうどんってやわやわなのね。なんか初めての体験。


ポスターをがっつりと見疲れて、休んでいたら@oec014と遭遇。水炊き気になるんだけどお一人さんはなぁみたいな話になり、じゃぁ行くかと。結果的に必然w
とり田に行ってみた。
お通しの半熟卵に肉味噌が敷いてあるやつ。すこぶる美味いのでビールではなく最初から日本酒頼んでおけばよかった。


白濁したスープが運ばれてきて、まずはネギしゃぶから。肉は「骨付き」「むね」「もも」の三種類


ゴマサバの味噌がけ。これも日本酒だったな

続いてつみれ鍋にしてもらいます。これを食べているとかしわ天が運ばれてきた。


最後に雑炊にしてもらった。

あとはデザートにプリンだけどicloudの同期がまだなのでそのうちアップする。
01122019 Haskell
2年ぶりの開催です。私が勢いだけで作った貴重な歴史的資料によると2012年にはコミュニティとして活動してるんですよね、、、なんかその頃は伊豆半島にHaskellerが沢山いたしw
私は転職時に頂いた圏論の歩き方をネタに話しましたが次回はもう少しHaskellに寄せたネタを考えておきます。
家を出たら富士山が白くなっていることに気づく。それからお昼食べる暇がなかったので駅そばで済ました。


懇親会はリパブリューで。最近プログラミング界隈のコミュニティに出ていなかったので色々と新鮮な話を聞けた。 それから@polidogとはなにげに初対面であることに驚かれた。なんかすれ違い多かったみたい。
なにげにここのところ、twitterではフォローしあってるけど初めて会うっていうのが結構多いですね。
あとは、アカウントわからないけどオフラインで私のtweetのリプライされるのも結構多い。初対面の人に「いつもtwitter見てます。で、この前こうtweetしてたじゃないですか?あれってどういうことなんですか?」みたいな。これは製薬特有の現象かもしれないが。




それからShizuoka.pyやりましょうっていう話もでたんで、近いうちに日程を決めますね。コミュニティFだとちょっと不便なのでプラサヴェルデでも取っておきます。
macosをcatalinaに上げたらperlで書いていた画像をリサイズしてサーバーにアップロードするプログラムが動かなくなって困ったのでpythonで書き直した。
それにしてもこれいつ書いたんだろう?
#!/usr/bin/env perl use strict; use warnings; use DateTime::Format::Epoch::Unix; use DateTime; use Image::Imlib2; use Net::OpenSSH; my $tp = $ARGV[0] || ""; my @files = do{ opendir my $dh, '.' or return; my @f = grep /\.(JPG|jpg|jpeg|PNG|png)$/, grep !/^\./, readdir($dh); closedir $dh; @f; }; my $ssh = Net::OpenSSH->new('XXXXXXX'); $ssh->error and die "SSH connection failed: " . $ssh->error; for my $infile (@files) { my $now = DateTime::Format::Epoch::Unix->format_datetime(DateTime->now); my $outfile = "/Users/kzfm/images/blog/" . $now . ".jpg"; my $image = Image::Imlib2->load($infile); unless ($infile =~ /^DSCN/ ) { unless ($tp) { if ($image->width > $image->height) { $image->image_orientate(1); }}} my $image2 = $image->create_scaled_image(320,0); $image2->set_quality(95); $image2->save($outfile); $ssh->scp_put($outfile, "/usr/local/html/images/blog/" . $now . ".jpg") or die "scp failed: " . $ssh->error; printf "\n",$now,$now; sleep(1); }
これをpythonで書き直した。
#!/usr/bin/env python from PIL import Image import time from datetime import datetime from glob import glob import paramiko import scp import os width = 400 img_dir = "/Users/kzfm/images/blog" remote_dir = "/usr/local/html/images/blog/" def get_epoc_name(): return str(int(time.mktime(datetime.now().timetuple()))) def save_resize_image(filename): en = get_epoc_name() resize_file_name = "{}.jpg".format(en) f = os.path.join(img_dir, resize_file_name) img = Image.open(filename) height = round(img.height * width / img.width) img = img.resize((width, height), Image.LANCZOS) img = img.rotate(-90, expand=True) img.save(f) return (f, en) if __name__ == "__main__": with paramiko.SSHClient() as sshc: sshc.set_missing_host_key_policy(paramiko.AutoAddPolicy()) sshc.connect(hostname='0.0.0.0', port=0000, username='XXX') with scp.SCPClient(sshc.get_transport()) as scpc: for f in glob("*.jpeg"): fname, en = save_resize_image(f) scpc.put(fname, remote_dir) print("".format(en)) time.sleep(1)
 密閉型モニターヘッドホン オーバーイヤーヘッドフォン 折り畳み DJステレオヘッドホン スタジオレコーディング/楽器練習/ミキシング/TV視聴/映画鑑賞/ゲームなどに対応 (pro002-1)
密閉型モニターヘッドホン オーバーイヤーヘッドフォン 折り畳み DJステレオヘッドホン スタジオレコーディング/楽器練習/ミキシング/TV視聴/映画鑑賞/ゲームなどに対応 (pro002-1) 料理の四面体 (中公文庫)
料理の四面体 (中公文庫) RNA-Seqデータ解析 WETラボのための鉄板レシピ (実験医学別冊)
RNA-Seqデータ解析 WETラボのための鉄板レシピ (実験医学別冊) 実験医学 2019年6月 Vol.37 No.9 細胞内の相分離〜タンパク質や核酸分子を整理し、反応の場を作り、生命を駆動する
実験医学 2019年6月 Vol.37 No.9 細胞内の相分離〜タンパク質や核酸分子を整理し、反応の場を作り、生命を駆動する 実験医学 2019年11月 Vol.37 No.18 再定義されるタンパク質の常識〜古典的なセントラルドグマの刷新と未開拓のタンパク質の世界
実験医学 2019年11月 Vol.37 No.18 再定義されるタンパク質の常識〜古典的なセントラルドグマの刷新と未開拓のタンパク質の世界 次世代シークエンサーDRY解析教本 改訂第2版
次世代シークエンサーDRY解析教本 改訂第2版





















 生命科学者のためのDr.Bonoデータ解析実践道場
生命科学者のためのDr.Bonoデータ解析実践道場 圏論の歩き方
圏論の歩き方