
pep8をGrowlで通知させるようにして数日経つが、Emacsを左右に分割するようになった(今までは上下に分割)
pep8の一行79文字以内におさめるという規約のおかげで左右に分割すると読みやすい。
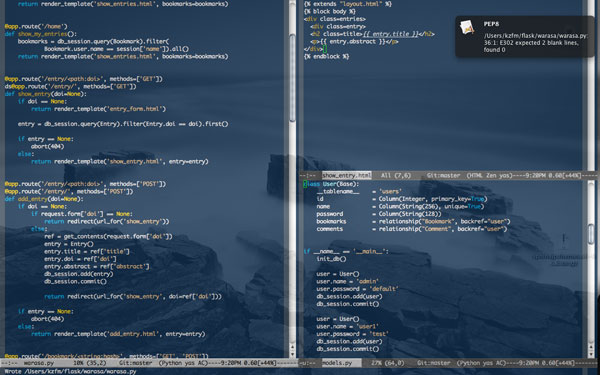
ちょっと生産性が上がった感がある。
pep8をGrowlで通知させるようにして数日経つが、Emacsを左右に分割するようになった(今までは上下に分割)
pep8の一行79文字以内におさめるという規約のおかげで左右に分割すると読みやすい。
ちょっと生産性が上がった感がある。
09062011 life
先週の静岡インフラ部で色々勉強になったので、空いてるマシンでkickstartしてみた。ちなみに次回は7/9ですが、インフラ系オススメの本を熱く紹介したりしなかったりという会になるらしいです。インフラの本なんてあんま知らないなぁ、どうしようかなぁと思案中。
それから6/25は富士でjavascript読書会も予定されているのでチェキの方向で。
まずはFC13が入ってたけど震災後さくらのVPSに取って代わられすっかり用済みになったマシンにCentOS5.6を入れた。まぁこれは普通に時間がかかったが、OSインストールするとそんなモンでしょう。ナニゲに家マシンにCentOS入れるのは初めてだった。
続いてキックスタート用に/root/anaconda-ks.cfgをUSBメモリにコピー(kz.cfgって名前にした)。この時にマウントポイントをチェックしておく。
で、再度DVDからのブート時に
linux text ks=hd:sda1/ks.cfg
これで、あとは完了までほっとくだけでいいのかなぁと思ったが、HDDを初期化すんのか?とhdaとsdaどっちにインストールするんや?と聞かれた。これも設定ファイルに書いておけんのかな。
上のコマンドだけで最後のインストール終了リブート待ちまで持っていくにはどうすんのかなぁ。
ムカシナツカシのプログレスバー
キックスタートは結構便利ですね。これにpuppetの設定まで書いておくといいのかなぁ。
これは名著かも
今、あなたが仕事や日々の暮らしで思ったとおりの結果を得ていないのなら、戦略的な人生設計にたちかえるときだ。失望や不満を感じるのは、腰を落ち着けて戦略的に取り組むべきだという合図である
本書は最も大切なポイントを見極める力の大切さを説いていてそこに焦点を当てることを説いている。
重要度と緊急度の軸があった場合に重要だが緊急でない仕事に割く時間を増やそうとか、そういこと。
基本的にポジティブ、オプティミスティックでやるべきことにフォーカスしようっていう内容ですね。たまに読みなおすと負のモードに陥らなくて済むのでいいと思う。
一方で、重要でないけど緊急な仕事を如何にやらないかという割と現実にありがちな部分には触れてなかったりするのは、そもそも想定してないからだろう。
もっとも重要な人生の選択とは、現在と未来の自分の姿に、全て自分が責任を取ると決めることである
っていう状況で、敢えて後ろ向きな対応をする必要がないからだろう。
色々勇気づけられる本であることは間違いないので読むといいですね。
07062011 Python
pep8ってコマンドが便利すぎてちょくちょく叩くんだけど、それでも叩くの面倒になったりすることはある。正直、こういうチェッカーは空気を読んで走って欲しいですね。
ユニットテストに組み込んでるのを見つけて、おーいいじゃん素敵じゃんとか思ってたんだけどもうちょい身近に感じたいなぁと。
で、Growlの出番。セーブするたびにpep8チェックが走って結果が通知されるようにした。
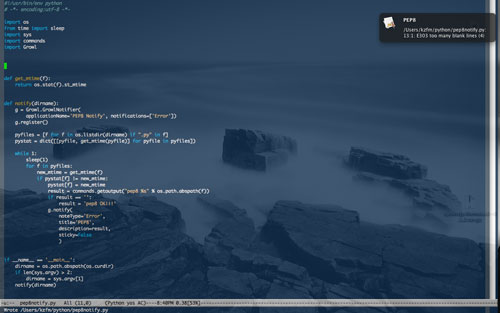
でもこの通知はすぐに消える(はやすぎ)。どこがおかしいのかよく見ようとすると消えてしまってちょっと困る。逆にstickyをTrueにすると消えずに残っているのでそれはそれでうざい。
神の御加護ってのはそんなもんなのかなぁと思った。あと、アイコンをPythonの蛇ロゴにしたほうがいいかなぁと。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | #!/usr/bin/env python # -*- encoding:utf-8 -*- import os from time import sleep import sys import commands import Growl def get_mtime(f): return os.stat(f).st_mtime def notify(dirname): g = Growl.GrowlNotifier( applicationName='PEP8 Notify', notifications=['Error']) g.register() pyfiles = [f for f in os.listdir(dirname) if ".py" in f] pystat = dict([[pyfile, get_mtime(pyfile)] for pyfile in pyfiles]) while 1: sleep(1) for f in pyfiles: new_mtime = get_mtime(f) if pystat[f] != new_mtime: pystat[f] = new_mtime result = commands.getoutput("pep8 %s" % os.path.abspath(f)) if result == '': result = 'pep8 OK!!!' g.notify( noteType='Error', title='PEP8', description=result, sticky=False ) if __name__ == '__main__': dirname = os.path.abspath(os.curdir) if len(sys.argv) > 2: dirname = sys.argv[1] notify(dirname) |
で、pep8走らせると長いStringが長すぎ!ってよく怒られるんだけど、長いURLとかしょうがないじゃん、無理して分割しても読みにくくなるじゃんと思うんだけどどうしたらよいんだろうか?
07062011 家庭菜園
天気予報だと午後から雨模様らしいので、朝起きてニンニクの収穫をしてきた。結構枯れてきてるので収穫期らしいが、写真の左下のほうに茎が曲がっておかしいのがあった。


こんな感じになってた。掘ってみたらニンニクの球が割れてたので、収穫が遅すぎのパターンってやつだった。

全部で11個収穫できた。初めてにしては満足の大きさではないかな。


薄皮をむいて綺麗にしてみた。

ニンニクは育て甲斐のある野菜だった。次はもうちょっと沢山植えようっと。
04062011 perl javascript
第1回 静岡ITPro勉強会 インフラ部で発表してきた。デモが動かなかったのは、名前がダサいという理由で電車の中でhtmlのファイル名を変えたせいでした、アホ過ぎる。
ま、こんな感じのファイルを用意します。AjaxでATNDのAPIにアクセスして今日の参加者を表示するっていうやつです。
<!DOCTYPE html> <html> <head> <title>ajaxtest</title> <script type="text/javascript" src="jquery-1.6.1.min.js"></script> </head> <body> <button id=ajax name="atnd">クリックするとユーザー一覧を表示します</button> <div class=users></div> <script> $("button#ajax").click(function(){ $.getJSON('http://api.atnd.org/events/users/?event_id=16076&format=jsonp&callback=?', function(data){ var items = []; $.each(data.events[0].users, function() { items.push('<li>' + this.nickname + '</li>'); }); $('<ul/>', { 'class': 'userlist', html: items.join('') }).appendTo('div.users'); }); }); </script> </body> </html>
これをスクレイピングするにはWWW::Mechanize::Firefoxを使って
use WWW::Mechanize::Firefox; use Web::Query; use Encode; my $mech = WWW::Mechanize::Firefox->new(); $mech->get('http://localhost:8000/'); $mech->click({ xpath => '//button[@name="atnd"]', synchronize => 0 }); sleep(2); #print $mech->content; my $q = Web::Query->new_from_html($mech->content); $q->find('li')->each(sub { my $i = shift; printf "(%d) %s\n", $i+1, encode('utf-8', $_->text); });
実行するとこんな風に出力されるはずです。
(1) secondarykey (2) ando_ando_ando (3) となか (4) yukio.47 (5) Kaz110 (6) tatsuya.ueda (7) taji_314159265 (8) kzfm (9) non
凡ミスでここまでは行かなかった。カナシス
04062011 life
あまり名言集は読まないのだけど、これは面白かったというより必読。普段あまりビジネス本を読まない人にとっても良書紹介としても良いかも。
知識労働者たるものは、自らの組織よりも長く生きる。したがって、他の仕事を準備しておかなければならない。キャリアを変えられなければならない。自らをマネジメントすることができなければならない
本書の中で、あとで読もうかなと思っている本をメモっておく
リーマン・ショック後の世界経済は金融危機を脱したとしても低い経済成長率が恒常化し、投資、雇用、生産性といったすべての成長が危機前より弱くなる状態が当たり前となる
ニューノーマルの勝者と敗者を分けるのは時間への取り組み方である。
これは読んだけどあとで読みなおす。
チャンスの追求者は、変化をともなう未来はチャンスをもたらすことを知っているが、問題解決者はどうしても過去を相手にしがちだ
いちばんつまらないのは、会社が何をめざしているのか、自分が何をしたいのかが曖昧のまま、ただ飼われるように働くことである
脳は、命令を嫌い、質問を好む傾向があります
致命的なミスを犯さずに、如何に小さなミスを繰り返せるかが重要なことだと書いてたひとがいたけど、そうだよなと思う。
人生は60%確実だと思ったことは成功するのである、100%の確率まで持っていったらチャンスは逃げてしまう
ドラッカー
02062011 javascript HTML5
先週末のjavascriptの読書会の懇親会で、スマートフォン用のサイトの話を聞いて、ネイティブアプリもwebアプリも作れるようになっとかなアカンなぁと勉強してみた。
本書はスマートフォンサイトを製作するには3つのアプローチがあって、本書では最初の二つを取り扱ってます。
全ページカラーで見やすいし、説明も丁寧なので入門書としてはオススメかと思う。小さい画面に対応するためにはというよりは、タッチパネルのような指で触るデバイスのインターフェースをどう設計するか、はまりどころはどこか?PC用のサイトとはどう違ってどういうところに気をつけるべきなのか?というあたりが知りたかったので本書は良かったですね。
個人的には1章は必要なくて、2章のCacooを利用した設計フローと4章の実践テクニックが役に立った。
基本的なところを押さえたらjQuery Mobileを使っていけばいいのかな。
 Pro Puppet
Pro Puppet Master of Puppets
Master of Puppets フォーカル・ポイント
フォーカル・ポイント

 エキスパートPythonプログラミング
エキスパートPythonプログラミング 本田直之「人を動かすアフォリズム」90
本田直之「人を動かすアフォリズム」90 ニューノーマル―リスク社会の勝者の法則
ニューノーマル―リスク社会の勝者の法則 マインドセット ものを考える力
マインドセット ものを考える力 自分ブランドの教科書
自分ブランドの教科書 脳が教える! 1つの習慣
脳が教える! 1つの習慣 野村再生工場 ――叱り方、褒め方、教え方 (角川oneテーマ21 A 86)
野村再生工場 ――叱り方、褒め方、教え方 (角川oneテーマ21 A 86) 高校生が感動した「論語」 (祥伝社新書)
高校生が感動した「論語」 (祥伝社新書) 人を動かす 新装版
人を動かす 新装版 勝てば官軍―成功の法則
勝てば官軍―成功の法則 ドラッカー名著集1 経営者の条件
ドラッカー名著集1 経営者の条件 ネクスト・ソサエティ ― 歴史が見たことのない未来がはじまる
ネクスト・ソサエティ ― 歴史が見たことのない未来がはじまる 客家大富豪 18の金言
客家大富豪 18の金言 話し方入門 新装版
話し方入門 新装版 ブライアン・トレーシーの 話し方入門 ー人生を劇的に変える言葉の魔力
ブライアン・トレーシーの 話し方入門 ー人生を劇的に変える言葉の魔力 誰とでも 15分以上 会話がとぎれない!話し方 66のルール
誰とでも 15分以上 会話がとぎれない!話し方 66のルール
 虹の風景 (青菁社フォトグラフィックシリーズ)
虹の風景 (青菁社フォトグラフィックシリーズ) iPhone+Android スマートフォンサイト制作入門 (WEB PROFESSIONAL)
iPhone+Android スマートフォンサイト制作入門 (WEB PROFESSIONAL)