
18022013 life
今年も、毘沙門天へ。
存続が危ぶまれている岳鉄だが、硬券だし、終電遅くなったしと、使用頻度は上がった。

ぶどう飴、バナナチョコ、たこ焼き、スーパーボールと娘と息子は楽しんでた。彼らのメインはこっちなので満足したようでなにより。
昨日はかなり寒くて風が冷たかったので、電車が待合室として使えるのはありがたい(ちょうど電車が来たので使ってないけど)。

緑の達磨を購入。

緑は健康祈願らしいが、今日早速息子が嘔吐性の風邪にかかった。
18022013 life
今年も、毘沙門天へ。
存続が危ぶまれている岳鉄だが、硬券だし、終電遅くなったしと、使用頻度は上がった。
ぶどう飴、バナナチョコ、たこ焼き、スーパーボールと娘と息子は楽しんでた。彼らのメインはこっちなので満足したようでなにより。
昨日はかなり寒くて風が冷たかったので、電車が待合室として使えるのはありがたい(ちょうど電車が来たので使ってないけど)。
緑の達磨を購入。
緑は健康祈願らしいが、今日早速息子が嘔吐性の風邪にかかった。
17022013 drum'n'bass
全体的にモクモク感が漂っていて、自分の中では盛り上がった。
高揚感はコントロールしづらいので、ドープで水面下ギリギリのテンションを保ちながらつなげられるようになるってのが課題だな。
Evs Dead / Wickaman & RV Tank / Ad Gannon Headbanger / Mikal Sound of the Rain / Royalston Adoration / SpectraSoul Wall Of Mirrors (Original) / SPY Perseverance (SPY Remix) / James Zabiela Love Has Gone (Dub Phizix Remix) / Netsky Whatever (Mefjus Remix) / Optiv & BTK Twang / Maztek Tension / Emperor Hovercraft / Quadrant Kid Hops & Iris Peace Love & Unity (feat. MC Fats) (Basher Remix) / DJ Hype Bassline Sinker (Original) / Joe Syntax Be One of Us / Wickaman & R.V One / Dan HabarNam
Mefjusやばすぎ
17022013 Python javascript
PhantomJSを触ってみたけど、スクレイピングというか自動化するならWWW::Mechanize::Firefoxのが使いやすいなぁと思った。
CasperJSを使うのがよさそうなんだけど、node.jsから使えないしなぁ。
例えばデータベースからurlリストを引っ張ってきて次々にアクセスしたいといった用途の場合、PhantomJSだったらphantomjs-nodeを使うらしいんだけどCasperJSはそういうことができるんだろうか?
と思って調べたら、SpookyJSというものを見つけたんだが、PhantomJSが1.8からwebdriverをサポートするようになったからそっち使えみたいな感じになっている。
結局pythonでselenium使うのが正解なのか?
ていうかseleniumでいいじゃんみたいな気分になっている。
17022013 Ti
スタッフの皆様お疲れ様でした。
後半のセッションが特に面白かったですね。

車情報連携ユニットが楽しそう。発表聞いていて、クルマもスマホと同じ持ち運ぶデバイスなんだなーと思った。電気自動車は充電するしなー。あとVelocityの意味でビッグデータの範疇に入っていくのかな。
最近ご無沙汰のAlloy。WidgetsとThemeが便利そうなので積極的に使っていこうと思った。ちなみに僕の開発環境は
なんだけど、ちょっと前にtylusっていうTSSをStylusで書くモジュールを発見したので使おうと思っている。

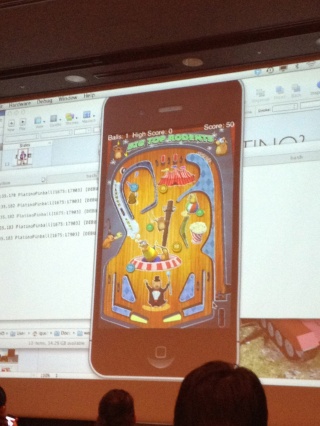
さくさく動いていてヤバイ、これは面白そう。Alloyでも動くそうだし。楽しみだ。
16022013 life
15022013 javascript coffeescript
Node.jsのときはMongoばかりなので実は使ってないことに気づいた。
sqlite3 = require('sqlite3').verbose() db = new sqlite3.Database('/tmp/blog.db') readAllRows = -> db.all "SELECT perma,title FROM entries", (err, rows) -> rows.forEach (row) -> console.log("#{row.perma}: #{row.title}") closeDb() closeDb = -> console.log "closeDb" db.close
出力
1355998432: PersistentのMigrationが便利そうだ 1356131853: カタカナのしりとりの圏 1356162470: ScottyはHaskellのSinatraクローン 1356235849: 本棚オーバーフロー 1356333890: virthualenvwrapperをつくった 1356341787: ブロッコリーとカリフラワーを畑とベランダで育てている 1356429473: yesod-tutorialがわかりやすい 1356515387: 24 Days of Hackage 1356521203: snapでさくっと作るウェブサーバー closeDb
15022013 life
筆者は計数感覚と提唱しているが。
15のハンバーガーを半額にした時の増益の理由の計算と、20の居酒屋オーナーの年収推定の計算のやり方が面白かったので、待ち時間に計算して暇つぶしをするという楽しみが増えた。
14022013 life
やっと行ってきた。新東名のSAからだったらすごく近い。が、新聞に載った直後らしく激混みだった。そしてみんな待ち時間にどうぶつの森をやっていた(老若男女問わず)。

いちごパフェといちごケーキ


いちごミルクとワッフル


美味しかった。また行きたい(平日に)。
14022013 javascript Backbone.js
Brunchで生成されるスキャフォールドよくわからんわーっていうのはChaplin.jsがわからんわーっていうことと同義だった。
Hello Worldのサンプルとostioのコードを読んでみたんだけど、いまいちわかってないところがある(HandlebarとかStylusをどこで組み込んでいるのかとか)ので、自分で一つ書いてみないとダメだなぁ。
いまのとこの理解だと、Chaplin.jsというのはBackbone.jsを土台にしたフレームワーク。backbone.layoutmanagerはBackbone.jsの拡張っぽいなぁと思ったがこっちはフレームワークな感じなので規約とかお作法っぽいものが多い。
他にドキュメントからだと、
という感じで役者が増えている。
13022013 life
速読
「コンセプトとはパーセプションの変容を促すもの」という表現は良かった。
ターゲティングで求められていることは、誰も考えなかったような細分化の尺度を考えることです
これもなるほどなーと思った。
しかし、略歴見たけど実績が書かれてなかった。マーケティングプランナーはあまり実績を表に出さないものなのだろうか?
 芸術闘争論
芸術闘争論 会社数字がわかる計数感覚ドリル (朝日新書)
会社数字がわかる計数感覚ドリル (朝日新書) ゆさぶる。企画書
ゆさぶる。企画書