
15072013 R
3連休の初日はグダグダしていたのだけど、残りの2日はそれなりに時間を確保してひと通り読んだので、積み残したところをメモ
 入門 機械学習
入門 機械学習- ヘルドアウトデータって言い方あまり聞いたことなかった
- Rのoptim関数
- curve(sapply( func...))がちょっと良くわからんので調べる
- リッジ回帰を理解した。というよりバイアス-バリアンス分解がちゃんと分かった気が
- .Machine$double.eps
- 暗号解読のコードを走らせると30分くらいかかる
PRML読みなおす
15072013 R
3連休の初日はグダグダしていたのだけど、残りの2日はそれなりに時間を確保してひと通り読んだので、積み残したところをメモ
PRML読みなおす
13072013 家庭菜園
モロヘイヤを定植してきた。育てるのは簡単のなので種で購入したほうが良いですね。一袋で二三年分くらいはあるし。夏は嫌になるほど摘める。

空芯菜もマルチかけて育てたらえらいことになった。毎週採れてお得。モロヘイヤと空芯菜は先端の柔らかいところをつまなきゃいけないんだけど、その手間が面倒だということで周りでは誰も植えていない。

ゴーヤの花が咲いていた。夏か。空芯菜は安定して収穫できている。


落花生はどうなのかなぁ。写真とっておいて今度いけたにさんに見せないと。最近ご無沙汰だから近々行こうと思っているが、日本酒の切れるタイミングが悪い。ミニトマトは安い苗(一株68円)だけど良くなっている。ベランダに植えたトマトベリーはヒョロヒョロだ。やっぱり畑のほうが育ちがいい。


人参は元気

オクラの花が咲いてた。去年はちゃんと収穫しなかったら巨大化させすぎては破棄するということを繰り返し、隣の畑のおじさんに笑われたので、今回はちゃんと収穫しようと思う。というよりオクラの味噌漬けという酒に合いそうな料理をみつけたので頑張れるはず。

梅雨明けた
モロヘイヤはそろそろ摘めそう。

ナスがたくさん採れた。空芯菜もかなりの量。人参は取らないとまずいが、消費しきれてない。シソは二株あれば十分。ゴーヤは小さい実がついてた。オクラも大きくなってた。

11072013 sake
一白水成の特純と庭のうぐいすのスパークリング。一白水成は綺麗目の味わいで夏に飲むと気分が良くなる。庭のうぐいすのスパークリングはスルスルいけすぎて超危険。すぐ空いた。


葵天下は静岡らしい酒かな。キリッとしていて飲みごたえがあった。


大那は夏酒のホタルと五百万石。夏酒は飲みやすいんだけど、ちょっと物足りなかった。というわけで五百万石のほうが好み。

Traktorにはicecastクライアントがついているので、サーバーを立てれば現在かけている曲名などを取ることができる。 radrなんかが有名かなと思うが、自分のやりたい方向性とはちょっと違う(ライフログとしてのDJingに興味がある)ので、Pythonで実装してみている。
Pythonでsocketプログラミングって初めて。
import socket import re HOST = 'localhost' PORT = 8000 connected = False artist_title_re = re.compile("ARTIST=(.*)TITLE=(.*)vorbis") s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.bind((HOST, PORT)) s.listen(1) conn, addr = s.accept() print 'Connected by', addr def response_ok(conn): conn.send('HTTP/1.0 200 OK\r\n\r\n') while 1: data = conn.recv(8192) if not data: break if not connected: response_ok(conn) connected = True at = artist_title_re.search(data) if at: print at.group(1), at.group(2) conn.close()
期間限定でお安くなっているS4が欲しい
09072013 chemoinformatics Python
pychembldb使えば楽勝だというということの証明をしようと思ったが、意外に面倒くさかった。
という条件でデータを引っ張ってくる。その後構造数<2のファイル(MMPにならない)を削除して、メタデータ(アッセイID, Uniprotのアクセッション番号、一般名称、データ元のジャーナル)を吐き出したあと、活性データをTSVに出力するようにしている。
最初はsdfのほうに活性情報も付けておけば楽勝じゃないかと思ったが、スキーマ見てたら測定タイプが正規化されてないうえに、AssayじゃなくてActivityのほうについてることに嫌な予感がしたので調べた。
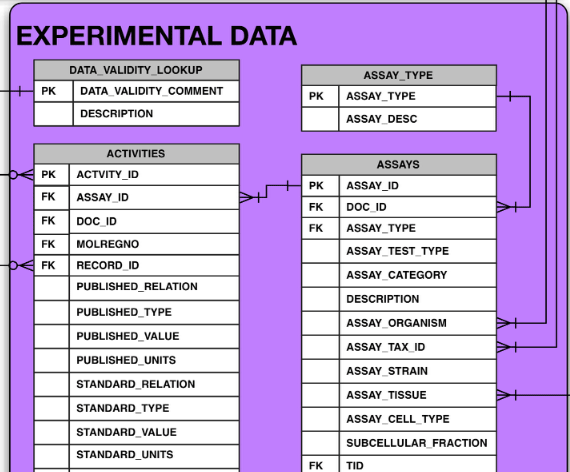
やはり、pIC50とIC50が混在してたり、InhibitionとIC50が混在していた。
これはペアに出来ないので僕の場合はpandasでゴニョるのでこうしましたが、PPのスキルが高まっていてこっちでやれるのであればsdfに活性入れておいたほうが取り回しやすいかも。
コードはexamples/recreation.pyにあります。ファイル名があれなのは今朝コードを買いている時にスーパーカーを聴きまくっていたからというわけなので察してください。
09072013 chemoinformatics Python
IC50とKiのトレンドをChEMBLのデータセットから探るという論文を読んでいたら、データ抽出のフィルターにconfidence level == 9を入れていたので、これは何かなぁと。
>>> from pychembldb import * >>> for c in chembldb.query(ConfidenceScore).all(): ... print c.description ... Default value - Target unknown or has yet to be assigned Target assigned is non-molecular Target assigned is subcellular fraction Target assigned is molecular non-protein target Multiple homologous protein targets may be assigned Multiple direct protein targets may be assigned Homologous protein complex subunits assigned Direct protein complex subunits assigned Homologous single protein target assigned Direct single protein target assigned
これはキュレーターが付与してるのかな? そうだとしたらかなりありがたい分類だ。
Direct single protein にアサインされているアッセイ数を調べてみる
>>> from pychembldb import * >>> c9 = chembldb.query(ConfidenceScore).filter_by(description="Direct single protein target assigned").one() >>> len(chembldb.query(Assay).filter_by(confidencescore=c9).all()) 76773
09072013 life
普通に合格してました。勉強時間等はFP(関数プログラマー?)3級を受けてきたを参考に。
良かったこと
特に厚生年金保険料の労使折半は詭弁だろうと。サラリーマンから自営業に転身する場合にはこの部分は考慮して設計しないといけない。
最後の健康保険も計算の仕方を理解したので任意継続にするか国民保険に切り替えるか判断つくようになったし、まぁ色々と勉強になった。
08072013 R
先週のShizuoka.py #2では@secondarykeyがpythonでやる機械学習の話をしていましたが、入門機械学習はRです。
回帰の章と正則化あたりをやる予定です。そんなに事前知識は要らないと思いますので、ちょっともつカレー気になるわーっていうヒトがいたらはじめてでも気軽に参加してもらえればと。
ちなみに僕はもつカレーを食べたことないので、期待度大な感じですね。
08072013 Python
先週のShizuoka.py #2で実務として一番勉強になったのが、Ansibleの話やserverspecといった構成管理やそいつらのテスト話であった。
さすがにリード開発者からメンション飛んできたら使わざるを得ないw
研究用のWSは個人でバラバラに管理していて、僕以外のマシンのPythonのバージョンがやたら古かったりして並列計算したいときに苦労したり、3人しかいないのに中途半端なLDAP管理になっていたりしていて残念すぎる環境なので改善したい。
07072013 chemoinformatics
こんな感じで
from pychembldb import * for a in chembldb.query(Assay).filter(AssayType.assay_desc == "Binding").distinct(): a.description
 パターン認識と機械学習 上
パターン認識と機械学習 上 NATIVE INSTRUMENTS TRAKTOR KONTROL S4
NATIVE INSTRUMENTS TRAKTOR KONTROL S4