RDKItはインストールが面倒くさいのと、実務だとPipelinePIlotとかOpenEye使うだろうからさらっと流すかも。その分iGraphのいじり方を多めに説明するかもしれない。
まだスライドに手をつけてないからわからないけどw
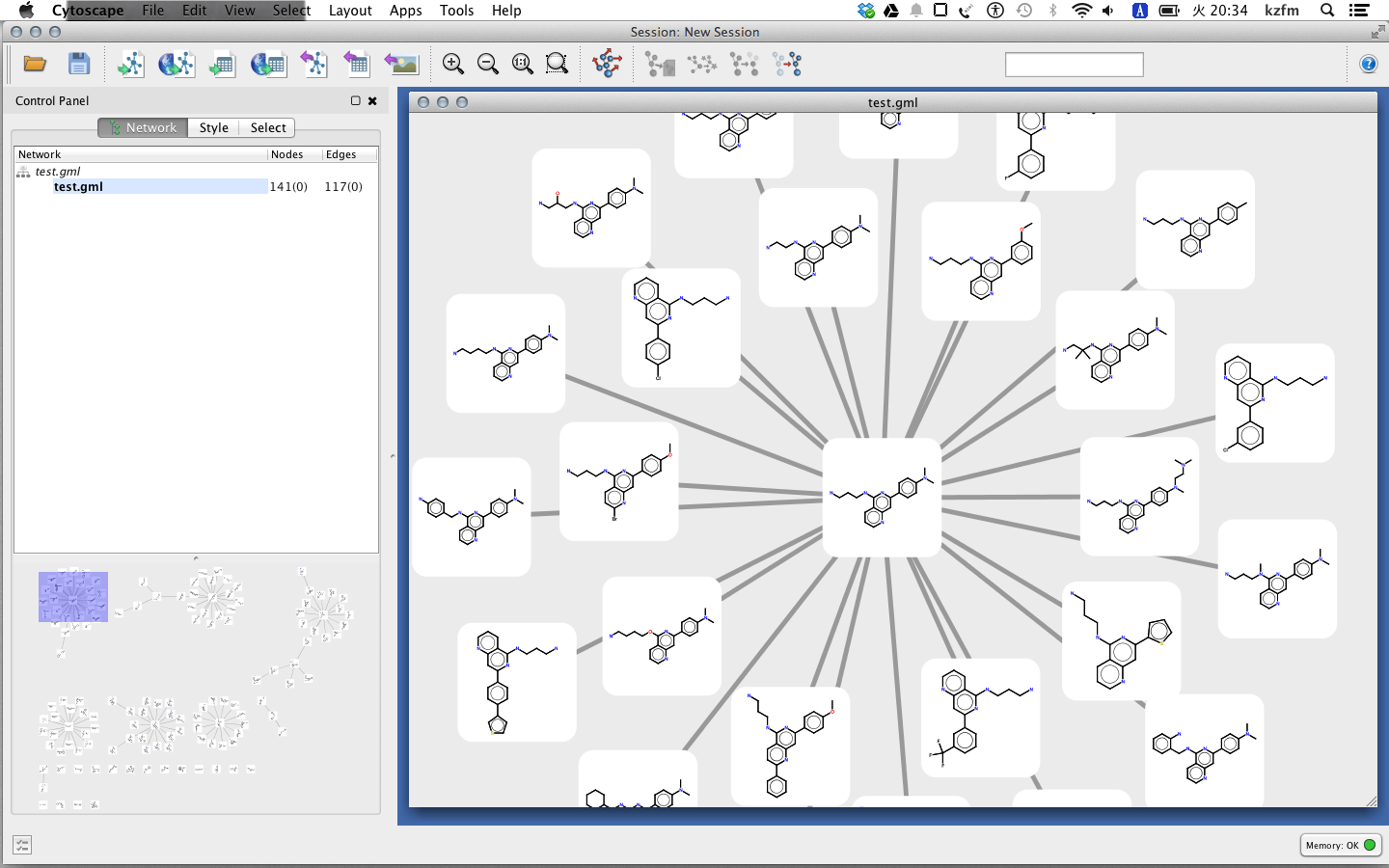
iGraphを使えばノードとエッジに属性を簡単に付加できてgml形式で出力できる。このファイルはすぐにCytoscapeで開くことが出来て便利です。sifとかタブ区切りテキストは色々と面倒ですね。
from rdkit import Chem
from rdkit.Chem import AllChem, DataStructs, MolToSmiles
import numpy as np
from igraph import Graph
import numpy as np
import logging
logging.basicConfig(level=logging.DEBUG)
threshold = 0.5
suppl = Chem.SDMolSupplier('syk.sdf')
fps = [AllChem.GetMorganFingerprintAsBitVect(mol, 2) for mol in suppl]
smiles = [MolToSmiles(mol) for mol in suppl]
mat = []
for i in range(len(fps)):
mat.append([DataStructs.FingerprintSimilarity(fps[i],fps[j]) for j in range(len(fps))])
sm = np.array(mat)
def search_root(sm, remain):
cand = None
max_c = 0
for l in remain:
num_c = len(np.where(sm[l] > threshold)[0].tolist())
if num_c > max_c:
max_c = num_c
cand = l
return cand
def check_edge(sm, current, root):
cand = None
max_c = 0
candidates = set(np.where(sm[root] > threshold)[0].tolist())
for c in candidates:
if c in current:
if sm[root, c] > max_c:
max_c = sm[root, c]
cand = c
return cand
edges = []
sim_edges = []
np.fill_diagonal(sm, 0)
remain = set(range(len(sm[0])))
current = set()
new = set()
ith = 1
while remain:
logging.debug("### {} th ###".format(ith))
ith += 1
root = search_root(sm, remain)
if root is None:
break
logging.debug("root: {}".format(root))
cand = check_edge(sm, current, root)
if cand:
logging.debug("connect {} and {}".format(cand, root))
edges.append((cand, root))
current.remove(cand)
sm[:, cand] = 0
remain.remove(root)
sm[:, root] = 0
for i in np.where(sm[root] > threshold)[0].tolist():
if i in remain:
edges.append((root, i))
sim_edges.append(sm[root, i])
new.add(i)
logging.debug("new nodes: {}".format(new))
current |= new
remain -= current
new = set()
g = Graph(edges)
g.vs["smiles"] = smiles
g.es["similarity"] = sim_edges
g.save("test.gml")

 ネットワーク分析 (Rで学ぶデータサイエンス 8)
ネットワーク分析 (Rで学ぶデータサイエンス 8)


 四間飛車を指しこなす本〈2〉 (最強将棋塾)
四間飛車を指しこなす本〈2〉 (最強将棋塾)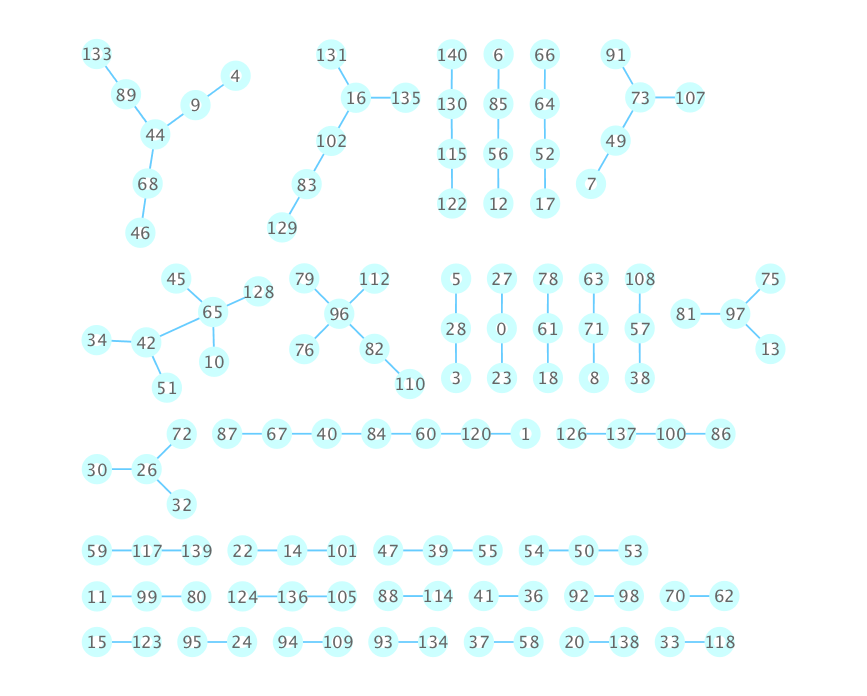



 作りおきそうざい
作りおきそうざい ひと目の中飛車
ひと目の中飛車