色々勉強になり充実した二日間でした。皆様お疲れ様でした。
こういう立場のヒトもいるってことで参加に至った背景(+α)をちょっと書いておきますね。
僕自身は完全にドライな立場のバイオ(ケモ)インフォマティシャンで、手火山式やでってくらいカッチカチの乾燥タイプです。そして、 うちの職場にはウェットなNGSの人材(普通のマイクロアレイとかDNAチップを扱う人材も)はいません(重要)。
じゃぁ、なんでNGSのデータ解析すんの?っていうことになるんですが、僕は企画調査的な立場で公共のデータをゴニョゴニョしたりする必要がたまにあるんだけど、最近NGSのデータって増えてきているわけです。公共データの使い方を知らなければ「分からない☆」と無知で通せるので幸せなんですが、流石にそれは自分のキャリアを考える上でよろしくないわけです。で、年末にちょっとそういった仕事が入ってきたので、いいタイミングだなぁと年始にDRY本を読んでいたんですがところどころ実験を理解していないとわからないようなところがあって消化不良だったところにハンズオンが丁度開催されたので参加したわけです。
具体的にはQCのところだったんですが、実際に実験やっている人だったら機械や手法にどういう癖があって、だからこういうあたりに注意してQCするとかそういうことを意識しながらトリミングしたりするんでしょうが、そこら辺の間隔が分からなかったので参加して非常に勉強になりました。それからウェットの参加者の割合が比較高かったせいか講師の方が「実験やっている方ならわかると思いますが」っていうあたりは押さえておくべきことがらなんだろうなとメモった。
それから、基本的に発現解析だけ押さえておけばいいかなと思っていたんだが、やはりChIP-seqも勉強しとかなあかんかなと思った。推薦されていたのはこの本だったかな?
あと DAVIDを知ることができたのが良かった。あれは便利そう。他にはMetascapeも良いらしいく、調査が捗る感ある。
最後にハンズオンやっていてちょっと気になったあたりをメモっておきます。
Pipe(|)
隣のヒトにPipeを使ったコマンドの意味を聞かれたのだけど、unix初心者にパイプって馴染み薄いよなと思った。level2で
みたいな記述がいくつかみられるんだけど
のほうがわかりやすいかも
R関係
- p.117のextdataPathをpasteする必要はないと思う
- p.118はsend <- csDendro(my.genes)とするべき
ダウンロード関係
p.105でebiにwgetするという記述があって、年始に写経した時にこの部分で結局3日取られてデータ取得もDRY本のネックやなと感じたけど、これはよく考えたら(考えなくてもw)DDBJからダウンロードするべきで、DRA Searchにアクセッション番号を入れて検索すればいいとのこと。
ただ、これはちょっとステップを踏むのでスクリプトを書いてみた。
wget `python draget.py ERR266338`
こんな感じでデータが取れる
お食事
たまに僕のタイムラインに握りの盛り合わせが投稿されるw もろこしずしで地魚丼を食べた。寒すぎて握りの気分ではなかったので次回はおまかせにぎり8貫で攻めたい

二日目の帰りにはつこでちょっと引っ掛けるかと思い寄ってみたが休みだった。facebookで告知して欲しいところ。

その後やごみも振られて、蕎麦宗は休日だし、濃いものは嫌だとダラダラと駅に向かったら香香についてしまったw
ピータンと砂肝の唐揚げをつまんで帰った。




 リピート (文春文庫)
リピート (文春文庫) ヘルシープログラマ ―プログラミングを楽しく続けるための健康Hack
ヘルシープログラマ ―プログラミングを楽しく続けるための健康Hack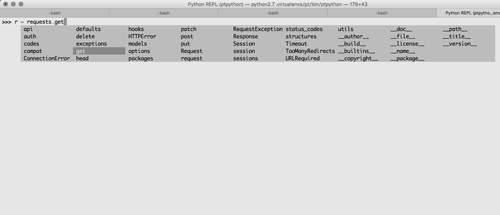
 杯が満ちるまで―しずおか地酒手習帳
杯が満ちるまで―しずおか地酒手習帳


 次世代シークエンサーDRY解析教本 (細胞工学別冊)
次世代シークエンサーDRY解析教本 (細胞工学別冊) 次世代シークエンス解析スタンダード〜NGSのポテンシャルを活かしきるWET&DRY
次世代シークエンス解析スタンダード〜NGSのポテンシャルを活かしきるWET&DRY








