
01032017 Python
ドットの前にスペース入れるらしい。解決するのに大分かかったのでメモ
>>> print "{:.1f}\n{:.1f}".format(1.0, -1.0) 1.0 -1.0 >>> print "{: .1f}\n{: .1f}".format(1.0, -1.0) 1.0 -1.0
01032017 Python
ドットの前にスペース入れるらしい。解決するのに大分かかったのでメモ
>>> print "{:.1f}\n{:.1f}".format(1.0, -1.0) 1.0 -1.0 >>> print "{: .1f}\n{: .1f}".format(1.0, -1.0) 1.0 -1.0
新宿久しぶり。
うどんでオイスターパクチー(オイパク)を食べてきました。タマリンドの酸味って梅干しっぽいね。

それから、久しぶりに酛にいった。昼酒万歳




今年こそ富山にホタルイカをすくいに行きたいなぁ。
今回も盛り上がって良かったです。大いに楽しみました。
懇親会も美味しかったので良かった。席数が100を超えてる店で開店近くの飛び込みなのにギリギリだったのには驚いたけど人気店なんだなと納得。接客すごく良かったです。

懇親会では色々ディープな話が聞けたけど、個人的には新しいmacbookproを思いとどまれたのが一番の収穫でした
早速帰ってから発注して、もう手元にあります(明日早起きして付け替え作業しようかなw)
それから、ドキドキするので発表時間は過少申告しないように気をつけましょうw
次回は夏くらいにまた西の方でやりたいですね。浜松の方でうなぎを食べるとかの美味しいものをセットにしたい。
15022017 monst
15022017 Python
週末はShizuoka.pyですので、SLに乗るなり、燕でラーメンを堪能するなり、楽しんでください。
尚僕はまだ資料に取り掛かってない、ヤバイ…
29012017 book
3年くらい放置していたけど、インフルエンザで一週間寝てたらついに読むものがなくなってしまったのでとうとう手を出してしまった。
結論、わけわからん。
27012017 work
この前の話をもうちょっとちゃんと書いてみる。
情報伝達とその重要度の軸としてはpush-pull,stock-flowというものがあって、pull,flow象限に対応する媒体に周知事項を流すとかpush,stock象限に対応する媒体にブロードキャスティングなお知らせ情報を送りつけるとかは良くない。
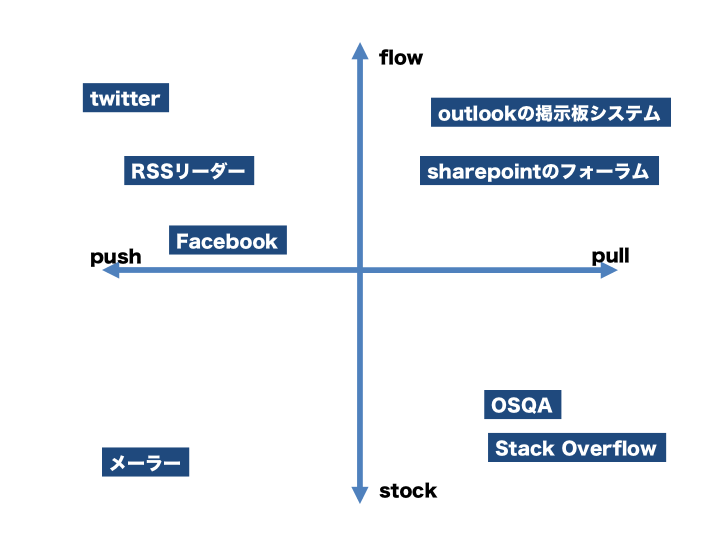
あともう一つ、data-knowledge,stock-flowという軸も考えられる。知識ベースを作りたいという欲求はどの組織にもあると思うんだけど、そういう場合基本的にpullな媒体を使うことになると思う。
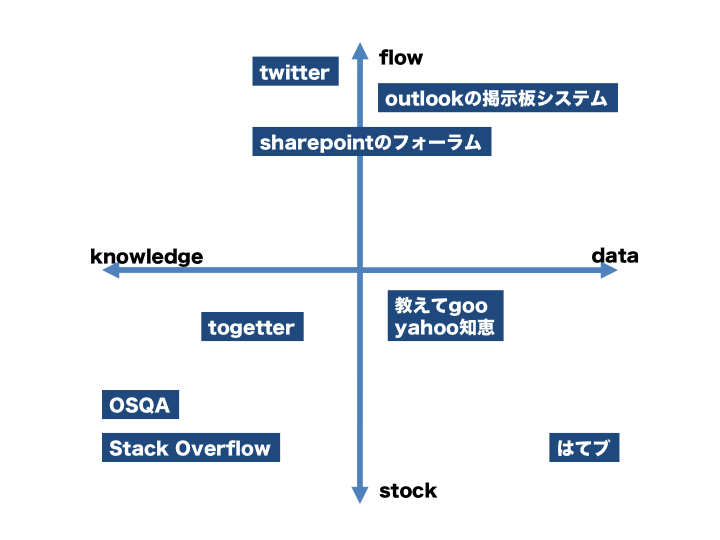
はてブのブックマーク自体は単にデータだし、コメント昨日は単なる意見の集合体だから知識とは言えない気がする。 あとtwitterも似たような感じだけど、なんとなくフォロワーを選べば知識に近い情報が流れてくることが多いのでまぁ有意義かなと思う。
掲示板システムみたいなのは議論が発散しがちだし、まとまらないのであんまり好きじゃない。
お手軽に書き込める掲示板システムみたいなもので知識ベースを作りたいっていうニーズを良く聞くんだけど、結局うまく行ったものを見たことないのは、データしか流れなくて知識の蓄積というところまでいかないせいだと思う。あの仕組みで上手くやるためにはキュレーター(かモデレーター)が必要なんだろうなぁと。
でもそれってキュレーターの主観とかはいるし、togetterはそういう部分透けて見える時があるから、ああいうのは本質的に難しいんだろう(査読論文も一緒だと思うし)
というわけで、今のところsofの仕組みが良く出来ているなぁと思うわけだが、母数が大きくないとあの仕組みがうまく動かないのが悩ましいところ。イントラQAシステム入れて、1000人以下の規模でも上手く動いている例があったら知りたい
26012017 food
シカ肉は自分で調理してみると結構臭いなぁとイズシカを扱ってみて感じた。肉屋のおじさんは唐揚げにすると美味しいって言ってたけどその通りだと思った。
っていうのが大きい理由なのかなと。
で、シカ肉を上手く調理するための本があったので読んでみた。
シカ肉調理は前処理が大切らしい
参考になった。
一方で、料理の写真は残念すぎたのとレシピは平凡すぎて普通の肉をシカ肉に替えただけのレシピがほとんどだった。特に写真はプロに頼めばいいのに…全く作る気にならんぞ、あれは。
26012017 life
追いインフルってやつを経験した(インフル自体も今まで経験した覚えはないが…)

結局土曜の夜からずっと寝ていた。当初は微熱が続いてだるいだけだったので月曜日に病院行ったら風邪だと診断されてグダグダしていたら、火曜の夜に強烈な喉の痛みと高熱が襲ってきて水曜日に再度通院したらインフルエンザAだった…
そのままイナビル注入したけど、高熱が治らなくて頭痛のせいで眠れず12時間後くらいに38度を切ってきた。朝はちょっと熱があったけど、起きたときには36度台になっていた。
イナビルすげーなと思った。
を試したけどロブよりロキソニンのほうが効き目が強い感じがした。カロナールはイナビル投与後に服用したけど全然熱が下がらなくて辛いままだった。
年末に虫垂炎が再発したし今年はなんか病気にかかりやすい気がするので体力づくりに励まないとあかんのかなと思っている。
一度年末に調整したのですが、タイミングが合わずにこの日にやることになりました。Shizdevのほうでも人工知能まわりをやっているので今回は共催となります。
python使いが静岡東部に多い+コミュニティFの利用料金が無料なのに綺麗という理由で最近のShizuoka.pyは富士でばかりやっていましたが、流石に他の地域で美味しいものを食べながらの懇親会をしなきゃなという理由で今回島田開催です。
尚、懇親会場は決まってないのでリクエストがあれば@fmkz___か@yajuまでよろしくお願いします。
島田のとなりの金谷には大井川鉄道があってSLが走っているので、鉄成分高めの方は満足するんじゃないかなぁと思います。僕は鉄成分がホメオパシー並に薄いのですが五和で撮ったとき(connpassの写真、今回は料理ではない)には「SLウォー!!!!」ってなりました。五和の中屋酒店に行った時にたまたま遭遇したんだけどねw
 WorldPlus バッテリー Apple MacBook Air 13 インチ 対応 A1405 A1496
WorldPlus バッテリー Apple MacBook Air 13 インチ 対応 A1405 A1496 海辺のカフカ (上) (新潮文庫)
海辺のカフカ (上) (新潮文庫) 海辺のカフカ (下) (新潮文庫)
海辺のカフカ (下) (新潮文庫) いけるね!シカ肉 おいしいレシピ60
いけるね!シカ肉 おいしいレシピ60