
06102012 Haskell
なぜか/usr/local/binのcabal(2010年製)を使っていたり、依存関係がぐちゃぐちゃになってしまい、Yesod入れようとしたら目眩のするようなエラーリストが生成されたりとグッタリ感満載の環境になってしまった。
全てをなかったことにしたいが、完全にきれいにするアンインストーラーは用意されてないみたいなのでそれっぽいのを消していく。
sudo /Library/Frameworks/GHC.framework/Versions/Current/Tools/Uninstaller sudo rm -rf /Library/Frameworks/HaskellPlatform.framework rm -rf ~/.cabal rm -rf ~/.ghc
/usr/binのシンボリックリンクとかも消せばいいんだろうけどもう一度インストールするので放っておいた。
(注) Haskell-Platform-2012.2.0.0には/Library/Haskell/bin/uninstall-hsというコマンドが用意されてました。
入れなおす。cabalを新しくしたらすぐにvirthualenvを入れる(超重要)。
open Haskell\ Platform\ 2012.2.0.0\ 32bit.pkg cabal update cabal install cabal-install-0.14.0 #0.16.0はvirthualenvがバグる cabal install virthualenv
新しいパッケージなんかを試したくなたらサンドボックスをつくる。例えばyesodを使いたい場合、適当なディレクトリを掘ってvirthualenvコマンドを叩くと.virthualenvディレクトリが出来てそこにcabalとか色々な設定がされる。
mkdir yesodtest
cd yesodtest
virthualenv
サンドボックス環境にするにはactivateする
source .virthualenv/bin/activate
cabal install yesod-platform
サンドボックス環境から抜けるにはdeactivateコマンドを叩けばいいし、要らなくなったら.virthualenvディレクトリを消せばいいだけなので、精神的によろしい。
 プログラミングHaskell
プログラミングHaskell XcodeによるObjective-C入門
XcodeによるObjective-C入門 よくわかるiPhoneアプリ開発の教科書【iOS 5&Xcode 4.2対応版】
よくわかるiPhoneアプリ開発の教科書【iOS 5&Xcode 4.2対応版】 詳解 Objective-C 2.0 第3版
詳解 Objective-C 2.0 第3版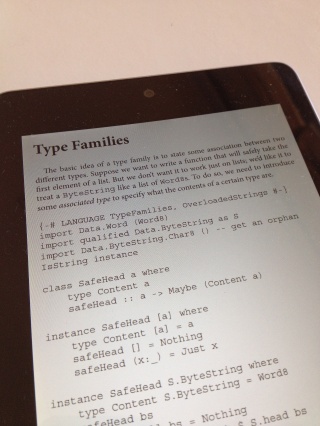
 Developing Web Applications With Haskell and Yesod
Developing Web Applications With Haskell and Yesod すごいHaskellたのしく学ぼう!
すごいHaskellたのしく学ぼう!

 Appcelerator Titanium Smartphone App Development Cookbook
Appcelerator Titanium Smartphone App Development Cookbook リーンソフトウエア開発~アジャイル開発を実践する22の方法~
リーンソフトウエア開発~アジャイル開発を実践する22の方法~ Real World Haskell―実戦で学ぶ関数型言語プログラミング
Real World Haskell―実戦で学ぶ関数型言語プログラミング