5.2のウェブアクセス数予測の節でRのコードは以下のようによくあるもの
> lm.fit <- lm(log(PageViews) ~ log(UniqueVisitors), data = top.1000.sites)
> summary(lm.fit)
Call:
lm(formula = log(PageViews) ~ log(UniqueVisitors), data = top.1000.sites)
Residuals:
Min 1Q Median 3Q Max
-2.1825 -0.7986 -0.0741 0.6467 5.1549
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.83441 0.75201 -3.769 0.000173 ***
log(UniqueVisitors) 1.33628 0.04568 29.251 < 2e-16 ***
---
これをpandas+scikit-learnでやってみる。プロットするのでipython -pylabで起動しておく。
from sklearn import linear_model
import pandas as pd
import numpy as np
top_1k_sites = pd.read_csv("top_1000_sites.tsv", sep="\t")
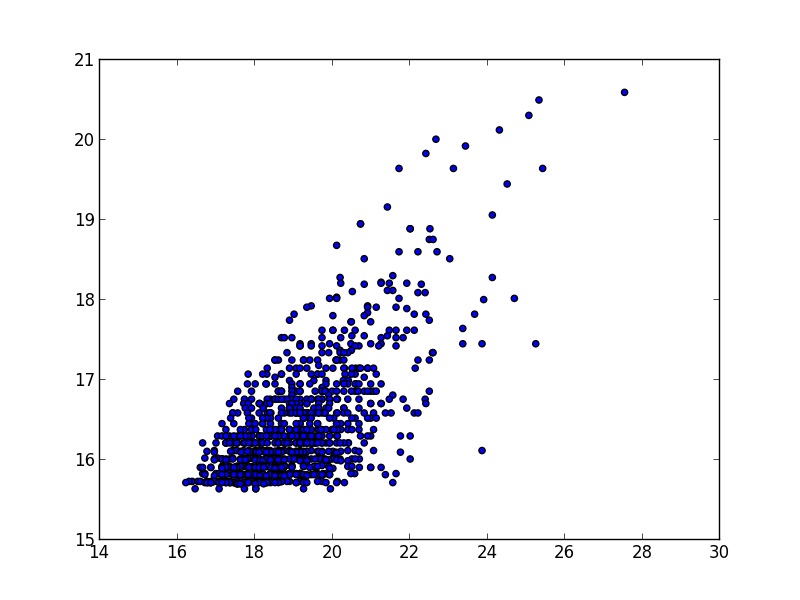
scatter(np.log(top_1k_sites["PageViews"]), np.log(top_1k_sites["UniqueVisitors"]))
clf = linear_model.LinearRegression()
clf.fit(np.log(top_1k_sites[["UniqueVisitors"]]), np.log(top_1k_sites["PageViews"]))
clf.coef_ # array([ 1.33627803])
clf.intercept_ # -2.834409473735672
個人的にRの表記の仕方(y ~ Xみたいな)のほうに慣れているのでscikit-learnのfit(X, y)という書き方は最初ちょっと戸惑った。
以下はscatter(np.log(top_1k_sites["PageViews"]), np.log(top_1k_sites["UniqueVisitors"]))で表示される散布図
 入門 機械学習
入門 機械学習
Drew Conway
オライリージャパン / 3360円 ( 2012-12-22 )






 In Rotation
In Rotation Bioisosteres in Medicinal Chemistry (Methods and Principles in Medicinal Chemistry)
Bioisosteres in Medicinal Chemistry (Methods and Principles in Medicinal Chemistry) ソラニン スタンダード・エディション [DVD]
ソラニン スタンダード・エディション [DVD] 良いウェブサービスを支える「利用規約」の作り方
良いウェブサービスを支える「利用規約」の作り方






 データ・サイエンティストに学ぶ「分析力」 ビッグデータからビジネス・チャンスをつかむ
データ・サイエンティストに学ぶ「分析力」 ビッグデータからビジネス・チャンスをつかむ