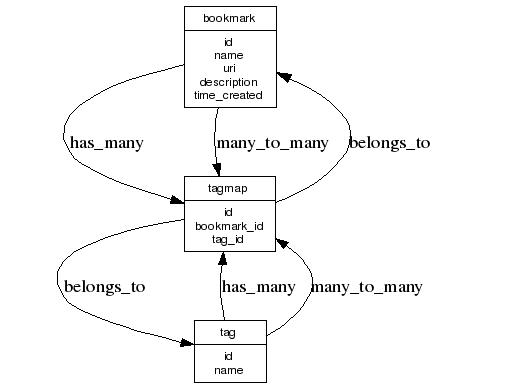
多対多のサンプルとしてTags: Database schemasの“Toxi” solutionをDBICで書いてみる。
関連を表すテーブルに対しては、1対多の関係を設定しておいて、更にmany_to_manyを追加する
図にしてみたらわかりやすくなった。
ちなみに、1対多はこちらを、多対多はこちらを参考にしました。
Kzfm::Schema
use 5.008008;
use strict;
use warnings;
use base 'DBIx::Class::Schema';
our $VERSION = '0.01';
__PACKAGE__->load_classes(qw/Tag Bookmark TagMap/);
1;
Kzfm::Schema::Tag
use strict;
use warnings;
use base 'Kzfm::Schema';
__PACKAGE__->load_components(qw/PK::Auto::SQLite Core/);
__PACKAGE__->table('tag');
__PACKAGE__->add_columns(qw/id name/);
__PACKAGE__->set_primary_key('id');
__PACKAGE__->has_many(tagmap => 'Kzfm::Schema::TagMap','tag_id');
__PACKAGE__->many_to_many('bookmarks' => 'tagmap','bookmark_id');
1;
Kzfm::Schema::Bookmark
use strict;
use warnings;
use base 'Kzfm::Schema';
__PACKAGE__->load_components(qw/PK::Auto::SQLite Core/);
__PACKAGE__->table('bookmark');
__PACKAGE__->add_columns(qw/id name uri description time_created/);
__PACKAGE__->set_primary_key('id');
__PACKAGE__->has_many(tagmap => 'Kzfm::Schema::TagMap','bookmark_id');
__PACKAGE__->many_to_many('tags' => 'tagmap','tag_id');
1;
Kzfm::Schema::TagMap
use strict;
use warnings;
use base 'Kzfm::Schema';
__PACKAGE__->load_components(qw/PK::Auto::SQLite Core/);
__PACKAGE__->table('tagmap');
__PACKAGE__->add_columns(qw/id bookmark_id tag_id/);
__PACKAGE__->set_primary_key('id');
__PACKAGE__->belongs_to('bookmark_id' => 'Kzfm::Schema::Bookmark');
__PACKAGE__->belongs_to('tag_id' => 'Kzfm::Schema::Tag');
1;
制約の部分だけ、考えてみる。
__PACKAGE__->belongs_to('カラム名(アクセサ?)' => 'スキーマ(pm)');
__PACKAGE__->has_many(テーブル名 => 'スキーマ(pm)','カラム名(アクセサ?)');
__PACKAGE__->many_to_many('任意のキー名' => 'テーブル名','多対多関係のカラム');
- belongs_toはまぁわかりやすい。
- many_to_manyは任意にキー名決められるのにhas_manyはキー値にテーブル名指定しないとエラー吐くのが謎。
- many_to_manyでテーブル名のとこをKzfm::Schema::TagMapってやるのが駄目な理由がよくわからない。
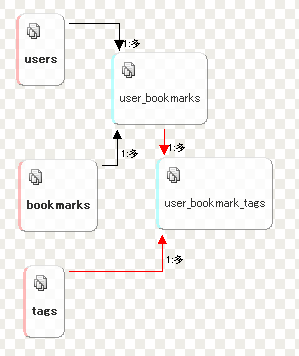
あと、さらにユーザーを追加する場合に、ユーザーとブックマークも多対多の関係になるけど、こっちも正規化したほうがいいのか、むしろやりすぎないほうがむしろいいのか悩む。
追記 06.12.04
ボケボケだったことに気付いた。