
15012007 meadow
いままで
M-x shell
と打って、シェルで作業してたのだけど
M-! command
で直接コマンドを実行できることが分かった。この差は結構でかかった。
15012007 meadow
いままで
M-x shell
と打って、シェルで作業してたのだけど
M-! command
で直接コマンドを実行できることが分かった。この差は結構でかかった。
14012007 Python
Meadowいじってて、補完機能使ってたら偶然見つけた。
M-x run-python
Meadowからpython使えると便利。
14012007 Meadow
emacs/Meadow用subversionインターフェースの使い方忘れてる。
ので、メモしておく
M-x svn-status m # コミットしたいファイルをマーク c # コミット # コメント入力 C-c C-c
こんな感じ
14012007 Food
週末は大体家族で買い物に出かける。昨日も近くのスーパーに買い物に出かけたわけだが、いつもは普通に88円とか98円とかで売っている納豆がやたら高い(128円)。
しかも、品揃えが少ない
といった状況に違和感を覚え、昨日は納豆を買わずに帰ってきた。今日も出かけたついでに別のスーパーを覗いたのだけど、
納豆がない、一個も!!
もげーーなんじゃこりゃーーってことで帰ってきてググッたら、
どうやらあるある効果らしい。
おそるべし、あるある、、、煽る煽る大辞典か。
この後は普通に
納豆関連株!旭松食品、篠崎屋!?|株のお姉さんの「株の教則」
四季報で調べたら、旭松食品2911というのが納豆主力の企業。篠崎屋2926もそうかしら。まだ、動いていないけど注目かも
ほう、なるほど。
14012007 java
そういえば、去年の今頃も結城浩さんのJavaのデザパタ本読んでたなぁ。
で、今度はリファクタリングの本を出すそうです。
きれいなソースは読むのが楽で、修正するのが楽で、デバッグするのが楽です。これに対して、きたないソースはすべてが大変です。ではどうすれば「きれいなソース」になるのでしょう。きたないソースをどうすれば(新たなバグを出さずに)きれいなソースにできるのでしょう。それに対する試みの1つが「リファクタリング」です。
本書『Java言語で学ぶリファクタリング入門』では、 Java言語を使って、リファクタリングの本質をていねいに解説します。
かなり欲しげ。というわけで、書籍プレゼント企画に応募した。
13012007 HyperEstraier
Lingua::JA::Summarizeで特徴語を抽出して、Hyper Estraierでblosxomのデータを検索するということをやってみた。
抽出された語彙は単にOR検索しているので、精度があんまよくない。
use strict; use warnings; use Estraier; use Lingua::JA::Summarize; my $entry = << '__DDD__'; 文章をここへ __DDD__ my $s = Lingua::JA::Summarize->new; $s->analyze($entry); my @keywords = $s->keywords({ minwords => 3, maxwords => 5}); my $query_keywords = join(" OR ", @keywords); print $query_keywords; my $db = new Database(); # open the database unless($db->open("/usr/local/blosxom/casket", Database::DBREADER)){ printf("error: %s\n", $db->err_msg($db->error())); exit; } my $cond = new Condition(); $cond->set_phrase($query_keywords); $cond->set_max(5); $cond->add_attr('@uri ISTREW .txt'); my $result = $db->search($cond); my $dnum = $result->doc_num(); foreach my $i (0..$dnum-1){ my $doc = $db->get_doc($result->get_doc_id($i), 0); next unless(defined($doc)); my $uri = $doc->attr('@uri'); printf("URI: %s\n", $uri) if defined($uri); my $title = $doc->attr('@title'); printf("Title: %s\n", $title) if defined($title); # display the body text # my $texts = $doc->texts(); # foreach my $text (@$texts){ # printf("%s\n", $text); # } } unless($db->close()){ printf("error: %s\n", $db->err_msg($db->error())); }
文書の類似性検索だったら文書をHyper Estraierに登録してから、類似度検索をかければいいのかも。estseek.cgiのsimilar検索みたいのがやりたいんだけど。Hyper Estraierのドキュメントをちゃんと読まねば。
13012007 hyperestraier
Lingua::JA::Summarizeの特徴語をHyper Estraierで検索 できるようにしたんだけど、特徴語を単にOR検索しているだけなので、精度がよくない。それが気に入らないので類似性検索までできるようにしてみた。
User's Guide of Hyper Estraier Version 1 (Japanese)
estseek.cgiの場合、「[similar]」というリンクを選択すると類似検索を行うことができます。
[SIMILAR] WITH 重み 語彙 WITH 重み 語彙 ...
という構文で類似性検索をする。さらに、類似性評価に関しても触れている。
User's Guide of Hyper Estraier Version 1 (Japanese)
類似度はベクトル空間モデルという考え方に基づいて算出されます。文書からキーワードを取り出してベクトルとして表現し、ベクトル同士のなす角の余弦を類似度とするものです。
余弦を類似度ってことはユークリッド距離でなくてコサイン距離を測ってるってことだな。つまり、プロファイル(波)の形の類似性を評価してるんだよね。図はOOoのCalcで(not Excel)。
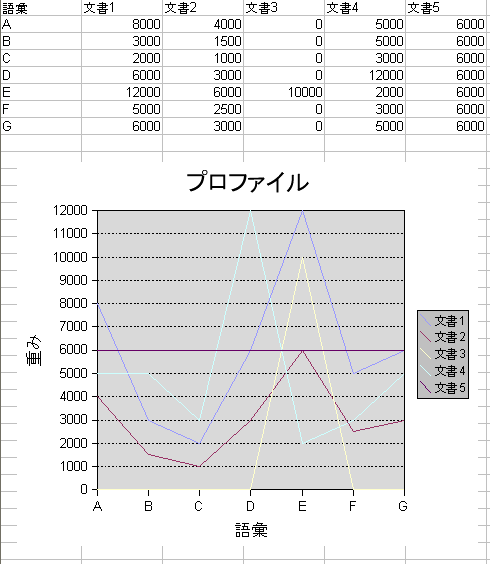
例えば、文書1と文書2は類似性が高い(とういか同一)だ。また、文書4のように一定の重みを均等に載せて直線としてプロファイルを定義してやっても、文書3みたいなOR検索でヒットしてしまうノイズは結構除ける。
[SIMILAR] WITH 10000 catalyst WITH 10000 plugin WITH \ 10000 tagcloud WITH 10000 markdown
実際にsimilar_entryプラグインを上記のような検索式に変更したら、かなり精度が上がった気がする。重みが10000ってのはblosxomのestseek.cgiの類似性検索の重みを眺めて適当に決めた。
重みを10000とかに決めうちしてしまっても結構使えそうなことはわかったんだけど、どうせならLingua::JA::Summarizeから重みを決定したい。
ドキュメント読んでみたら、statsっていうメソッドで統計的なデータが求められるらしい。statsメソッドは、こんな感じでハッシュで返ってくる。
$VAR1 = { 'r' => { 'cost' => 2000, 'count' => 1, 'weight' => '5.55555555555556' }, 'forest' => { 'cost' => 2000, 'count' => 3, 'weight' => '55.5555555555556' }, 'バギング' => { 'cost' => 2000, 'count' => 1, 'weight' => '11.1111111111111' },
cost*weightを利用すればよいような感じだけど、これはTFIDFの意味合いでよいのだろうか?
たつをの ChangeLogとか、奥 一穂のお仕事ブログをよく読んでみると、それっぽくは使えるようだ。コメント欄など参考になった。
CRFはMecabのサイトから論文たどれる。
以下、参考資料
Hyper EstraierもLingua::JA::Summarizeも大体解決したので後は実装するだけ。といっても以前作ったコードにちょっと手を加えrるだけ。重みを10で割ってるのは意味ない(気持ち的にそうしたかっただけ)
my @keywords = $s->keywords({ minwords => 3, maxwords => 16}); my $stat = $s->stats(); my $query_keywords = "[SIMILAR] " . \ join(" ", map "WITH " . \ int($stat->{$_}->{cost} * $stat->{$_}->{weight}/10) . \ " $_", @keywords);
こんな感じでEstraier用のクエリを構築してあとはAPIつかって検索するだけ。blosxomのsimilar_entryプラグインはこれで検索結果を表示するようにした。
以下、メモ。
13012007 R
Rで並列計算(とりあえず、動いたので報告です。256ノードで動かすと、さすがに速いです。修正大歓迎。)
snowパッケージを用いてクラスターマシン上で並列計算を行う。
Rで並列計算できるらしい。
早速試したいが、いま自由にできるまとまったクラスターがないのでまた後で。
でも、PCAとか速くなると嬉しい。
12012007 msys
linuxで実行時間の計測に使うtimeコマンドがDOS窓だと、
>time test.exe 入力された時刻は受け付けられません。 新しい時刻を入力してください:
とまぁ時刻入力になってしまい、ムキーとなるわけだが、MSYSのシェルからだとちゃんと実行される
$ time test.exe real 0m0.046s user 0m0.061s sys 0m0.000s
ということに気付いた。
12012007 LDR
夏過ぎからずっとbloglinesと併用していたのだけど、 livedoor Readerに完全に乗り換えた。クリップしやすいのとサクサク読めるので。
でもSBSは相変わらず、del.icio.usだ。
アイコンがあるから、お気軽感が強いのかナァ。てかあの場所は目につくからブックマークレットに比べて分かりやすい。

livedoor クリップにもこういう拡張機能用意されんかな。
と思ったが、SBSは既読未読考えなくてよいから、単にdel.icio.usと同期するようにすればいいのかな。
 増補改訂版Java言語で学ぶデザインパターン入門
増補改訂版Java言語で学ぶデザインパターン入門