
13 01 2007 hyperestraier Tweet
Lingua::JA::Summarizeの特徴語をHyper Estraierで検索 できるようにしたんだけど、特徴語を単にOR検索しているだけなので、精度がよくない。それが気に入らないので類似性検索までできるようにしてみた。
Hyper Estraierの類似性検索の仕組み
User's Guide of Hyper Estraier Version 1 (Japanese)
estseek.cgiの場合、「[similar]」というリンクを選択すると類似検索を行うことができます。
[SIMILAR] WITH 重み 語彙 WITH 重み 語彙 ...
という構文で類似性検索をする。さらに、類似性評価に関しても触れている。
User's Guide of Hyper Estraier Version 1 (Japanese)
類似度はベクトル空間モデルという考え方に基づいて算出されます。文書からキーワードを取り出してベクトルとして表現し、ベクトル同士のなす角の余弦を類似度とするものです。
余弦を類似度ってことはユークリッド距離でなくてコサイン距離を測ってるってことだな。つまり、プロファイル(波)の形の類似性を評価してるんだよね。図はOOoのCalcで(not Excel)。
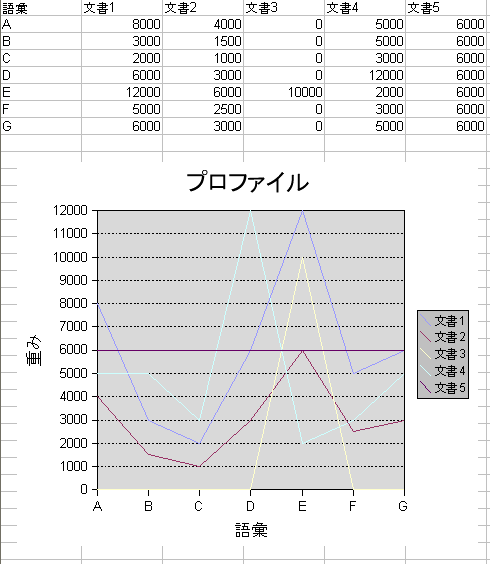
例えば、文書1と文書2は類似性が高い(とういか同一)だ。また、文書4のように一定の重みを均等に載せて直線としてプロファイルを定義してやっても、文書3みたいなOR検索でヒットしてしまうノイズは結構除ける。
[SIMILAR] WITH 10000 catalyst WITH 10000 plugin WITH \ 10000 tagcloud WITH 10000 markdown
実際にsimilar_entryプラグインを上記のような検索式に変更したら、かなり精度が上がった気がする。重みが10000ってのはblosxomのestseek.cgiの類似性検索の重みを眺めて適当に決めた。
Lingua::JA::Summarizeから語彙の重みを取り出す
重みを10000とかに決めうちしてしまっても結構使えそうなことはわかったんだけど、どうせならLingua::JA::Summarizeから重みを決定したい。
ドキュメント読んでみたら、statsっていうメソッドで統計的なデータが求められるらしい。statsメソッドは、こんな感じでハッシュで返ってくる。
$VAR1 = { 'r' => { 'cost' => 2000, 'count' => 1, 'weight' => '5.55555555555556' }, 'forest' => { 'cost' => 2000, 'count' => 3, 'weight' => '55.5555555555556' }, 'バギング' => { 'cost' => 2000, 'count' => 1, 'weight' => '11.1111111111111' },
cost*weightを利用すればよいような感じだけど、これはTFIDFの意味合いでよいのだろうか?
たつをの ChangeLogとか、奥 一穂のお仕事ブログをよく読んでみると、それっぽくは使えるようだ。コメント欄など参考になった。
CRFはMecabのサイトから論文たどれる。
以下、参考資料
Lingua::JA::Summarizeの抽出語彙に重みをつけてHyper Estraierで類似性検索をする
Hyper EstraierもLingua::JA::Summarizeも大体解決したので後は実装するだけ。といっても以前作ったコードにちょっと手を加えrるだけ。重みを10で割ってるのは意味ない(気持ち的にそうしたかっただけ)
my @keywords = $s->keywords({ minwords => 3, maxwords => 16}); my $stat = $s->stats(); my $query_keywords = "[SIMILAR] " . \ join(" ", map "WITH " . \ int($stat->{$_}->{cost} * $stat->{$_}->{weight}/10) . \ " $_", @keywords);
こんな感じでEstraier用のクエリを構築してあとはAPIつかって検索するだけ。blosxomのsimilar_entryプラグインはこれで検索結果を表示するようにした。
以下、メモ。
- Lingua::EN::Summarize でpubmedのアブストラクトいじくるのも楽しいかも
- Lingua::EN::SummarizeとWWW::Patent::Pageとか組み合わせてもよさそう。
- Lingua::JA::Summarizeなどでの特徴語とSBSのタグってどういう関係になるんだろうか?気になる。