
年末に家族が相次いで風邪で倒れたりとか、出張が忙しかったとか、寒いとか、朝の日の出が遅くて出社前に畑仕事ができないとか、様々な理由でほうれん草と小松菜が植えっぱなしになっていた、家庭菜園に数カ月ぶりに行った。
小松菜でかくなりすぎ。んで菜の花になってた。

雑草多すぎ。抜いても抜いても取り切れん。明日早起きして草取りしようと心に誓った。

今年はもう少し計画的にいろいろ植えたい。
22032010 sake
島崎酒店で。
長野の新井近くの中野で醸されている酒。

やさしいめ。ぬる燗で美味くなる感じ。
新井のほうもARAI MOUNTAIN & SPAが営業停止になってからいってないなぁ。っていうか今シーズンも滑らずに終わりそう。
22032010 Scala
5章まで。6章はアクターで難しい(急激にスピードが落ちた)
変数名と型の間に =>を記述 def delayed (t: => long) {とか
これは結局クロージャみたいなもんを渡してるのかな?
scala> val x = () => "test"
x: () => java.lang.String = <function>
scala> x
res0: () => java.lang.String = <function>
scala> x()
res1: java.lang.String = test
scala> def y() = { "tttt" }
y: ()java.lang.String
scala> y
res2: java.lang.String = tttt
いまいちわからん。
Haskellでは(Int, Int) => StringとInt => Int => => Stringは同じですが、Scalaでは違います。
20032010 Python machinelearning
強化学習
 Machine Learning: An Algorithmic Perspective (Chapman & Hall/Crc Machine Learning & Patrtern Recognition)
Machine Learning: An Algorithmic Perspective (Chapman & Hall/Crc Machine Learning & Patrtern Recognition)いくつかの問題点も指摘されている。例えば Q学習による理論的保証は値の収束性のみであり収束途中の値には具体的な合理性が認められないため学習途中の結果を近似解として用いにくい、パラメータの変化に敏感でありその調整に多くの手間が必要であるなどがある。
19032010 music
明日から
18032010 chemoinformatics Python
ほとんど化合物情報をTokyo Cabinetで管理してみると同じノリで出し入れできそう。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | #!/usr/bin/env python # -*- encoding:utf-8 -*- import pybel import couchdb sdffile = "pc_sample.sdf" couch = couchdb.Server() db = couch.create('pubchem') mols = pybel.readfile("mol",sdffile) for mol in mols: title = mol.OBMol.GetTitle() molstring = mol.write("mol") db[title] = {"mol":molstring} |
化合物情報みたいな、RDBで管理しやすいようなデータよりは、in vivoの薬理試験とか動態試験みたいな、プロトコル間で比較があまりなくて、かつ所見とかの文章データが重要なもののほうが向いているのかもしれんなぁと思った。PKデータなんてIDで探して、時点と個体のデータがJSONで引っ張ってこれるようにしとけばナイスすぎる!
javascriptからRの関数呼べんかな?そうすればJSONでデータ受け取ってPKfitとか使えんのにな。それかbrewとか
書籍もいくつか出てるけど、日本語ないなぁ。そのうち出るんかな?
18032010 Python matplotlib machinelearning
遺伝アルゴリズム
Machine Learning: An Algorithmic Perspective (Chapman & Hall/Crc Machine Learning & Patrtern Recognition)Four Peaks Problemってのがあるらしい。目的関数が
目的関数はこんな感じ。
#!/usr/bin/env python
# -*- encoding:utf-8 -*-
from itertools import takewhile
def o(bits):
return len(list(takewhile(lambda x: x == 1,bits)))
def z(bits):
return len(list(takewhile(lambda x: x == 0,reversed(bits))))
def f(bits):
reward = 100 if o(bits) > 10 and z(bits) > 10 else 0
return max(o(bits),z(bits)) + reward
if __name__ == "__main__":
bits1 = [1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
bits2 = [1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
for bits in [bits1,bits2]:
print "score: %d %s" % (f(bits),bits)
#score: 20 [1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
#score: 114 [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
要するに素直に探索していくとローカルミニマムに落ちるようになっていて、ピークの数が4つあるのでFour Peaks Problem
連続した1,0の長さでcontour plotを描いた。
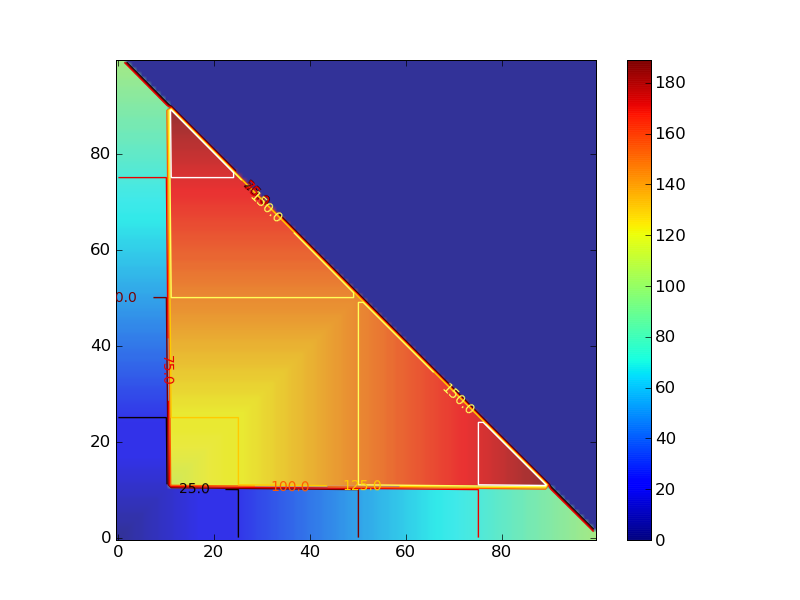
#!/usr/bin/env python
# -*- encoding:utf-8 -*-
def sim_score():
for x in range(100):
for y in range(100):
if x + y > 100:
yield 0
else:
score = four_peak(x,y)
yield score
def four_peak(x,y):
reward = 100 if (x > 10 and y > 10) else 0
score = max(x,y) + reward
return score
if __name__ == "__main__":
from pylab import *
delta = 1
x = arange(0, 100, delta)
y = arange(0, 100, delta)
X, Y = meshgrid(x, y)
Z = array([z for z in sim_score()])
Z.shape = 100,100
im = imshow(Z,origin='lower' ,alpha=.9)
colorbar(im)
cset = contour(X,Y,Z)
clabel(cset,inline=1,fmt='%1.1f',fontsize=10)
hot()
savefig('4peaks.png')
17032010 java
二年近く積んであったが、最近javaで書いてるので読んでみたら想像以上に面白かった。厚さの割にスラスラ読めたので、二日程度で読み終わった。
良書
後半は、パターンが解決したかった「もの」が多かったので、デザインパターンを知っていないと理解しにくいかもしない。逆に知っていればさらっと入ってくる。
17032010 macbook
macbookのHDDを交換したのでSoftware Design 総集編のpdfを入れてみた。
Spotlightで検索できるようになって便利。

 Scalaプログラミング入門
Scalaプログラミング入門 kikUUiki(初回限定盤)
kikUUiki(初回限定盤) CouchDB: The Definitive Guide
CouchDB: The Definitive Guide Beginning CouchDB
Beginning CouchDB Couchdb in Action
Couchdb in Action Java言語で学ぶリファクタリング入門
Java言語で学ぶリファクタリング入門 増補改訂版Java言語で学ぶデザインパターン入門
増補改訂版Java言語で学ぶデザインパターン入門 Software Design 総集編 【2000~2009】(DVD付)
Software Design 総集編 【2000~2009】(DVD付)