
16092013 Python
PyCon Sprintでちょっともくもくしてきた。
名前の由来はUAの曲から

16092013 Python
Pythonでオフィスのドキュメントを扱うというお話をしてきましたのでスライドをアップロードしました。
尚11-12月くらいに次のShizuoka.pyを開催する予定にしております
参考
ランチに名物のいも汁を食すかたは掛川駅に1130に集合です。
一応6回で終了すると思うので次回以降の読書会のネタに関しても話し合いたいので、なにか推薦する方は教えて下さい。
いまのところ、機械学習の延長線上にありそうな「実践コンピュータビジョン」はどうかなという話が上がっております。OpenCV+機械学習+Pythonという結構面白い本だと思います
01082013 Python
PyCon APAC 2013でpythonを使ったdocx,xlsx,pptx作成の話をさせていただけることになりました。
というのは宣伝で、応募に至るまでの経緯をちょっと書いておきます。
僕は製薬業界にいる関係でchemoinformaticsとかbioinformaticsとかmolecular docking simulationをずっとやっていたので、ライフサイエンス系でのpythonの適用事例くらいなら50分くらい余裕でしゃべり続けられるなぁということで当初はそういう応募をしようかなぁと考えていたんだけど、science with pythonのほうでも似たようなトークを応募するみたいだったんで、やっぱやーめた、放置。締め切りみたいな流れで6月は終わったわけです。
で、7/9まで締め切り延長になったけど別に応募する気ないしー参加するだけでいいやーと思って過ごしていたのだけど、締め切り延長4日前に行われたShizuoka.py #2に@aodagさんが急遽参加されて、懇親会の時に「なんか応募しないのー?しないのー?」というようなことを言われて、じゃぁなんかしとこうかなーという気分になって次の日勢いに任せて応募したという経緯。
で、採用されたと(嬉しい)。
というわけでパーフェクトPython書いましょう。
YAPCのスピーカーすごいす!、PyConのスピーカーすごいす!と参加者側でずっと過ごしてたけど、今回初めて発表するので、少しは皆さんの心に残るようなお話が出来たらいいなぁと思っています。
注1)高いところが苦手なので懇親会は躊躇している 注2)製薬業界以外の仕事にも興味があったりする
24072013 Python
cookbook的なものを読みながらお作法を覚えようとするとまず混乱するのだが、FAQにちゃんと書いてあることを発見した。
あとこれ
Pyplot provides the state-machine interface to the underlying plotting library in matplotlib. This means that figures and axes are implicitly and automatically created to achieve the desired plot. For example, calling plot from pyplot will automatically create the necessary figure and axes to achieve the desired plot.
ステートマシンだと知ってないとかなり戸惑うのと、figureなんだよ、どこから来るんだよ?となる。
plotというメソッドが用意されているので楽ちんと思ったがバッチの処理をさせたら同じ画像ばっかり生成されて小一時間ハマった。
いつものようにsofによるとcloseが必要らしい。
for experiment in experiments: exp.data.plot(x="Date", y="Val", style="ro", ) savefig("static/images/{}.png".format(exp.name)) close()
Traktorにはicecastクライアントがついているので、サーバーを立てれば現在かけている曲名などを取ることができる。 radrなんかが有名かなと思うが、自分のやりたい方向性とはちょっと違う(ライフログとしてのDJingに興味がある)ので、Pythonで実装してみている。
Pythonでsocketプログラミングって初めて。
import socket import re HOST = 'localhost' PORT = 8000 connected = False artist_title_re = re.compile("ARTIST=(.*)TITLE=(.*)vorbis") s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.bind((HOST, PORT)) s.listen(1) conn, addr = s.accept() print 'Connected by', addr def response_ok(conn): conn.send('HTTP/1.0 200 OK\r\n\r\n') while 1: data = conn.recv(8192) if not data: break if not connected: response_ok(conn) connected = True at = artist_title_re.search(data) if at: print at.group(1), at.group(2) conn.close()
期間限定でお安くなっているS4が欲しい
09072013 chemoinformatics Python
pychembldb使えば楽勝だというということの証明をしようと思ったが、意外に面倒くさかった。
という条件でデータを引っ張ってくる。その後構造数<2のファイル(MMPにならない)を削除して、メタデータ(アッセイID, Uniprotのアクセッション番号、一般名称、データ元のジャーナル)を吐き出したあと、活性データをTSVに出力するようにしている。
最初はsdfのほうに活性情報も付けておけば楽勝じゃないかと思ったが、スキーマ見てたら測定タイプが正規化されてないうえに、AssayじゃなくてActivityのほうについてることに嫌な予感がしたので調べた。
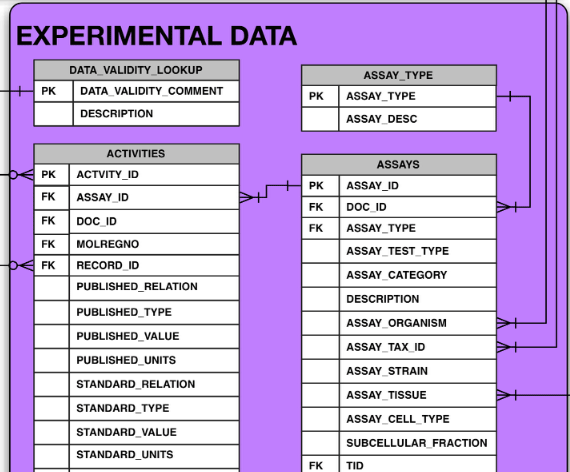
やはり、pIC50とIC50が混在してたり、InhibitionとIC50が混在していた。
これはペアに出来ないので僕の場合はpandasでゴニョるのでこうしましたが、PPのスキルが高まっていてこっちでやれるのであればsdfに活性入れておいたほうが取り回しやすいかも。
コードはexamples/recreation.pyにあります。ファイル名があれなのは今朝コードを買いている時にスーパーカーを聴きまくっていたからというわけなので察してください。
09072013 chemoinformatics Python
IC50とKiのトレンドをChEMBLのデータセットから探るという論文を読んでいたら、データ抽出のフィルターにconfidence level == 9を入れていたので、これは何かなぁと。
>>> from pychembldb import * >>> for c in chembldb.query(ConfidenceScore).all(): ... print c.description ... Default value - Target unknown or has yet to be assigned Target assigned is non-molecular Target assigned is subcellular fraction Target assigned is molecular non-protein target Multiple homologous protein targets may be assigned Multiple direct protein targets may be assigned Homologous protein complex subunits assigned Direct protein complex subunits assigned Homologous single protein target assigned Direct single protein target assigned
これはキュレーターが付与してるのかな? そうだとしたらかなりありがたい分類だ。
Direct single protein にアサインされているアッセイ数を調べてみる
>>> from pychembldb import * >>> c9 = chembldb.query(ConfidenceScore).filter_by(description="Direct single protein target assigned").one() >>> len(chembldb.query(Assay).filter_by(confidencescore=c9).all()) 76773
08072013 Python
先週のShizuoka.py #2で実務として一番勉強になったのが、Ansibleの話やserverspecといった構成管理やそいつらのテスト話であった。
さすがにリード開発者からメンション飛んできたら使わざるを得ないw
研究用のWSは個人でバラバラに管理していて、僕以外のマシンのPythonのバージョンがやたら古かったりして並列計算したいときに苦労したり、3人しかいないのに中途半端なLDAP管理になっていたりしていて残念すぎる環境なので改善したい。
 入門 機械学習
入門 機械学習 実践 コンピュータビジョン
実践 コンピュータビジョン パーフェクトPython (PERFECT SERIES 5)
パーフェクトPython (PERFECT SERIES 5) Python for Data Analysis
Python for Data Analysis NATIVE INSTRUMENTS TRAKTOR KONTROL S4
NATIVE INSTRUMENTS TRAKTOR KONTROL S4