
10032010 chemoinformatics Python network matplotlib
ふと、つぶやいた。
例えば
- プロジェクトで500検体合成
- ひとつの親あたり5-25化合物くらいの子を合成する
- プロジェクトの人員の制限により、一度に10ラインまでしか同時に走らない
- 11番目以降はそれ以降のオプティマイゼーションは行われない
その時知りたいことは、
- {計画、合成、アッセイ、解析}というサイクルは何回まわるのか、
- 有望そうな化合物だけど、人的リソースの関係で選択されなかった歴史はどこにあるか?
- バックアップ候補の化合物はどこら辺で現れるか(初期?中期?)
あたり。
現実の系に近づけるために、親化合物にはポテンシャルがあって、近傍探索すると、ポテンシャルの近くで活性が変化するモデル。あと同じライン(ブランチ)を継続して合成すると、ポテンシャル曲線が底に近づくのと、合成もSARに関する知識がついてくるので、活性は上がりやすくなって、かつ変動幅も小さくなるようにweightはだんだん小さくなるようにしてみた。
#!/usr/bin/env python
# -*- encoding:utf-8 -*-
# kzfm <kerolinq@gmail.com>
from random import random
import networkx as nx
import matplotlib.pyplot as plt
class Branch(object):
"""LeadOptimization flow"""
count = 0
@classmethod
def inc_count(cls):
cls.count = cls.count + 1
return cls.count
@classmethod
def get_count(cls): return cls.count
def __cmp__(self, other):
return cmp(self.act, other.act)
def __init__(self,potency,weight):
self.num = Branch.inc_count()
self.potency = potency
self.weight = weight
self.act = self.potency + self.weight * random()
def make_child(self,num_childs,potency,weight):
return [Branch(self.potency + self.weight * random(),self.weight * 0.7) for i in range(num_childs)]
if __name__ == "__main__":
max_comps = 500
initial_branches = 3
nodesize = []
nrange = []
erange = []
generation = 1
heads = [Branch(0.3,1) for i in range(initial_branches)]
G=nx.Graph()
for h in heads:
nodesize.append(h.act * 30)
nrange.append(generation)
while Branch.get_count() < max_comps:
new_heads = []
generation += 1
for branch in heads[:10]:
for new_comp in branch.make_child(int(5+20*random()),branch.potency,branch.weight):
nodesize.append(new_comp.act * 30)
nrange.append(generation)
erange.append(generation)
G.add_edge(branch.num,new_comp.num)
if new_comp.act > 0.75:
new_heads.append(new_comp)
heads = new_heads
heads.sort()
nx.draw_spring(G, node_size=nodesize, node_color=nrange, edge_color=erange,alpha=0.7, \
cmap=plt.cm.hot, edge_cmap=plt.cm.hot, with_labels=False)
plt.savefig("proj.png")
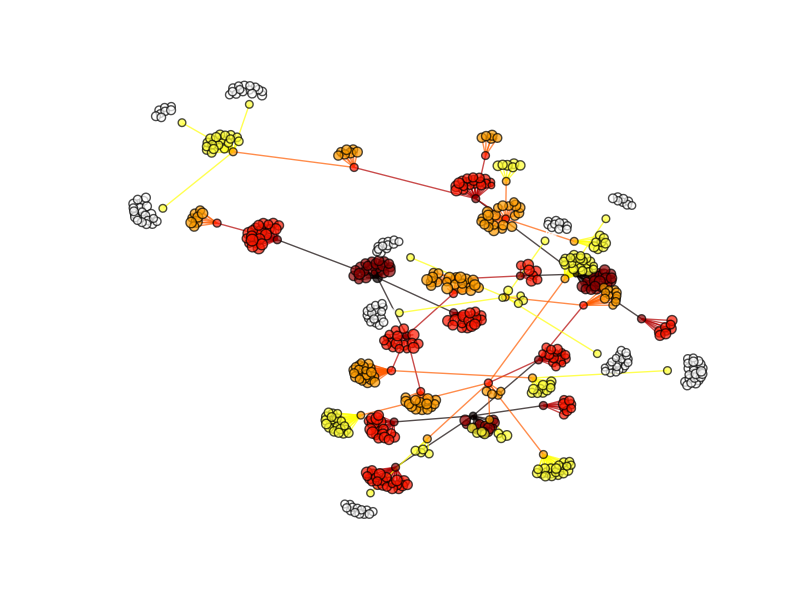
んーなんかいまいち。一応活性の強弱にあわせてノードのサイズが変わるようにしてみたんだけど、大きさがわからん。
 Machine Learning: An Algorithmic Perspective (Chapman & Hall/Crc Machine Learning & Patrtern Recognition)
Machine Learning: An Algorithmic Perspective (Chapman & Hall/Crc Machine Learning & Patrtern Recognition) パターン認識と機械学習 下 - ベイズ理論による統計的予測
パターン認識と機械学習 下 - ベイズ理論による統計的予測
 Machine Learning: An Algorithmic Perspective (Chapman & Hall/Crc Machine Learning & Patrtern Recognition)
Machine Learning: An Algorithmic Perspective (Chapman & Hall/Crc Machine Learning & Patrtern Recognition) Data Mining, Second Edition: Practical Machine Learning Tools and Techniques, Second Edition (The Morgan Kaufmann Series in Data Management Systems)
Data Mining, Second Edition: Practical Machine Learning Tools and Techniques, Second Edition (The Morgan Kaufmann Series in Data Management Systems) エキスパートPythonプログラミング
エキスパートPythonプログラミング