2人目産むの無理ゲーすぎるというエントリというか愚痴を読んで。給料が少ないとかそういうのは問題になっていないという空気感は取り入れてある。
頼れる実家が近くにあって、旦那も定時で帰ってくる、みたいな夢のような非実在家族
頼れる実家は近くにないけど、僕は基本的に定時で帰っている(妻は専業主婦ではないが正社員でもない)。僕の場合は朝はかなり早く出社するので残業していることになるけど、子供が病気になったら(積極的に)休みを取ったり、まぁそういう分担は普通。もしパートナー間で分担しない場合、専業主婦じゃないかぎり無理ゲーだし、専業主婦だとしてもかなりハードなんじゃないかなと思う。僕のまわりを観測してみると二人以上の子持ちはだいたい専業主婦だし、旦那はみんな遅くまで働いている気がするなぁ。
で、なぜ彼ら(旦那ね)は家庭へのコミットが少なくならざるを得ないのか?
それは社会がそういうシステムになっていてそれをみんなが肯定しているからでしょう。
会社における重要度緊急度マトリクス
自己啓発系によく説かれているように、重要度緊急度マトリクスのうちで大切にしなければならないものは第二象限の重要だけど緊急でないものですね。できるサラリーマンの皆さんは当たり前過ぎて言うまでもない。
じゃぁ第三象限ってなんなの?っていうのは素直に生じる疑問なんだけど、自己啓発系の本でこの象限に関しては言及が非常に少ないように思う。
僕は、既存の(特に年功序列が色濃く残る企業)においては、重要じゃないけど緊急だという第三象限をこなすことで、出世ポイントが貯まると解釈している。これに年功序列ポイントと労組ボーナスを加味して出世つまり給料の上昇という形で、自分の仕事へのフィードバックが行われるわけですね。
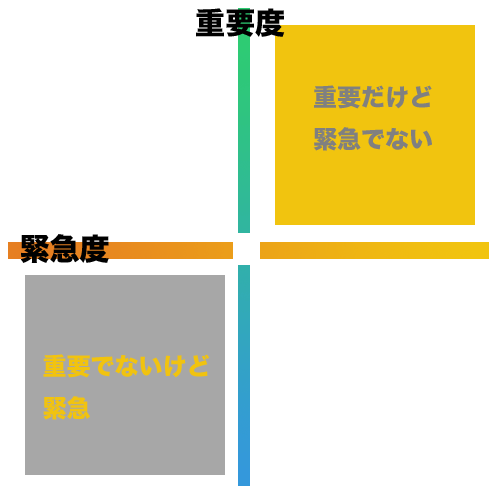
ただ、時間は万人にとって平等であり、大抵の場合、第二象限、第三象限を同時にカバーする余裕はないので選択を迫られるわけだ。
- 第三象限を切り捨てる
- 第三象限を残業という拡大仕事枠を用意して取り込む
大抵は後者を選択するせいで遅くまで働くことになり、2人目産むの無理ゲーすぎるのようにパートナーとの負担分担が難しくなっているのだろう。僕の場合は第三象限切り捨て派として暮らしているために、家族や子供のために使う時間はそれなりにあるが、最近特に出世のレールからは若干はみ出してるかなぁと感じている。
つまるところ、第三象限はムダというわけではなく(そもそも第一象限は差別化要因ではないために)会社はああいう重要でない割に緊急なものをどんだけこなすかで、会社に対する忠誠心を測っているのかなぁと。
なんというか「残業してまで第三象限的な仕事をこなす」 イコール 「会社にコミットしているのよ」というコンセンサスが取れているのがそもそも問題なんじゃないかなぁと。
一昔前の終身雇用型の労働環境だったらこれが生き方の選択としてごく普通だったんだろうけど、これからはこのやり方でいいのかなぁ?もっとちゃんと考えたほうがいいんじゃないのかなぁと思うんだけどどうなんだろうねー。
そんじゃーね











 販促の教科書 (1THEME×1MINUTE)
販促の教科書 (1THEME×1MINUTE) Open Source Software in Life Science Research: Practical Solutions in the Pharmaceutical Industry and Beyond (Woodhead Publishing Series in Biomedicine)
Open Source Software in Life Science Research: Practical Solutions in the Pharmaceutical Industry and Beyond (Woodhead Publishing Series in Biomedicine) 成功する人の「語る力」: 英国首相のスピーチライターが教えるライティング+スピーチ
成功する人の「語る力」: 英国首相のスピーチライターが教えるライティング+スピーチ