
plotというメソッドが用意されているので楽ちんと思ったがバッチの処理をさせたら同じ画像ばっかり生成されて小一時間ハマった。
いつものようにsofによるとcloseが必要らしい。
for experiment in experiments: exp.data.plot(x="Date", y="Val", style="ro", ) savefig("static/images/{}.png".format(exp.name)) close()
plotというメソッドが用意されているので楽ちんと思ったがバッチの処理をさせたら同じ画像ばっかり生成されて小一時間ハマった。
いつものようにsofによるとcloseが必要らしい。
for experiment in experiments: exp.data.plot(x="Date", y="Val", style="ro", ) savefig("static/images/{}.png".format(exp.name)) close()
21072013 R
@harumakiyukkoがShinyをtweetしてたので、今週末の読書会のサンプルコードをShinyで書くかと思ったんだけど、よさげな題材が見つからなかったので保留中。
これは分析者のための分析者による分析者のためのウェブアプリなので、非分析者との橋渡しにはならないだろうな。
15072013 R
3連休の初日はグダグダしていたのだけど、残りの2日はそれなりに時間を確保してひと通り読んだので、積み残したところをメモ
PRML読みなおす
08072013 R
先週のShizuoka.py #2では@secondarykeyがpythonでやる機械学習の話をしていましたが、入門機械学習はRです。
回帰の章と正則化あたりをやる予定です。そんなに事前知識は要らないと思いますので、ちょっともつカレー気になるわーっていうヒトがいたらはじめてでも気軽に参加してもらえればと。
ちなみに僕はもつカレーを食べたことないので、期待度大な感じですね。
23062013 R
第3回入門機械学習読書会お疲れ様でした。優先トレイ実装しました

なんとなく日替わりを注文してしまった。

美味いんだけど、他のヒトのマグロづくしをみたらマグロオンリーにしておけばよかったかなぁと。
懇親会はphotoにお邪魔してひとしきり楽しんだあと、ずっと気になっていたソビスケに。

まるで息をするかのようにマゲをかぶる、ここではそれが自然体という雰囲気が醸し出されていて、なんの疑問も抱かずマゲる我々

出てきたソビはコシがあって、美味しかった。最近蕎麦屋にいかなくなってしまったので久々に蕎麦だった。
ソビ湯は容器に入って出てきた。


次回は初の清水でやります。懇親会はもつカレーの食べられる店をチョイスする予定にしてます。
優先トレイと回帰分析の章をやります。
懇親会はどこにするかは決めていないですが、それほど人が多くなければPhotoに寄って、ソビって帰るというプランが(自分のなかで)固まりつつある。
ちなみに、scikit-learnでも回帰分析してみました。
5.2のウェブアクセス数予測の節でRのコードは以下のようによくあるもの
> lm.fit <- lm(log(PageViews) ~ log(UniqueVisitors), data = top.1000.sites) > summary(lm.fit) Call: lm(formula = log(PageViews) ~ log(UniqueVisitors), data = top.1000.sites) Residuals: Min 1Q Median 3Q Max -2.1825 -0.7986 -0.0741 0.6467 5.1549 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -2.83441 0.75201 -3.769 0.000173 *** log(UniqueVisitors) 1.33628 0.04568 29.251 < 2e-16 *** ---
これをpandas+scikit-learnでやってみる。プロットするのでipython -pylabで起動しておく。
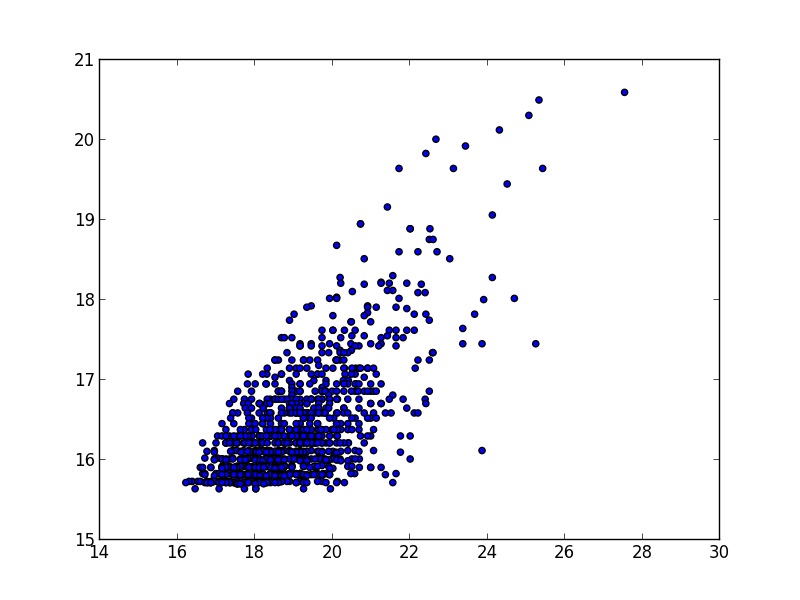
from sklearn import linear_model import pandas as pd import numpy as np top_1k_sites = pd.read_csv("top_1000_sites.tsv", sep="\t") scatter(np.log(top_1k_sites["PageViews"]), np.log(top_1k_sites["UniqueVisitors"])) clf = linear_model.LinearRegression() clf.fit(np.log(top_1k_sites[["UniqueVisitors"]]), np.log(top_1k_sites["PageViews"])) clf.coef_ # array([ 1.33627803]) clf.intercept_ # -2.834409473735672
個人的にRの表記の仕方(y ~ Xみたいな)のほうに慣れているのでscikit-learnのfit(X, y)という書き方は最初ちょっと戸惑った。
以下はscatter(np.log(top_1k_sites["PageViews"]), np.log(top_1k_sites["UniqueVisitors"]))で表示される散布図
26052013 R
二回目も無事に終了しました。入門機械学習にはベイズの定理の説明があまり書かれていなかったので、それっぽい資料にしてみましたが、箱というアナロジーはなかなか掴みにくかったのかも。
懇親会は筋肉系の居酒屋にお邪魔しました。なんかアイテムが増えてて、片手で50kgとか。酒飲みながら筋トレを楽しめる感じになっていた。というか、そういう世界があるというのも驚きだ。

焼き鳥についている辛味噌が良い感じ。

あと焼きそばは小辛でもかなり辛かった。
懇親会は後ほど用意します
ベイズ分類の章をやります。
今回は富士吉原開催なので、僕のオススメのつけナポリタンの店でも紹介しておきます。
つけナポ元祖。鉄板。

当初は速攻売り切れていたのだけど、最近はそんなこともないみたい。
かなり酸の効いた味で、日本酒に例えると杉錦天保13年
まったりカフェで食べるつけナポリタン


ワイン酒場になってた。コミュニティFの目の前なのでアクセスは良い。つけナポリタンの味も良かった。
あうのかあわないのかはっきりしろや!的なCLIを書いてみた。
自分のブログに似ているかどうかをベイズ分類しています。似てないのサンプルを集めるのが面倒だったけど、アメブロあたりから適当にチョイスしました。もちろん西野カナはあわないほうに分類しておいた。
一応、5/25の入門機械学習読書会の宣伝も兼ねているので、機械学習に興味があったり、つけナポリタンを食べたかったり、会いたかったり会えなかったりするヒトは参加するといいです。今日はPythonで書いていますが、次回の読書会では由緒正しきRでベイズ分類器を実装していきます。
例えば伊東のGentoo過激派と私の相性は
$ ./nk "http://blog.karky7.net/feeds/posts/default?alt=rss" きみにあうよ あうかな: ffmepgコマンドでmp4の動画からm4a(音声)を抜き出してみた あうかな: HACKING: 美しき策謀(第2版) がたまらなく面白い あうかな: gentooのpython-pptxで美人の水着画像をpptx化する あうかな: 静岡Python会、Shizuoka.py行ってきました あうかな: gentooのJuicyPixelsのebuildを作りました あうかな: gentooでudevのUpdateにはご注意下さい... あうかな: gentooで emacs + cscope を使ってタグジャンプでコードを飛びまくる あうかな: 2日酔いからPersistentでキーを使って直接データを引く あうかな: WebデザイナーこそGentooを使うべき4つの理由 あわない: 2013年 プログラマーの皆さん河津桜の季節です あうかな: Linuxでカーネルオプションを探す方法 あわない: 2013年 伊東オレンジビーチマラソン走りました あうかな: セガール君、お土産 in America あうかな: Sabayon Linuxにちょっと惹かれてしまった あわない: 新年の山走り行ってきました あうかな: HaskellのPersistent MySQLを試してみた あわない: 2012年大晦日オフロードツーリングへ行ってきたよ あうかな: LXCのネットワーク設定...続き あうかな: GentooでPersistent-MySQLのebuildを作ってみた あうかな: GentooのLXC(Linux Container)をやってみた あうかな: Gentooでemacs+haskell環境を作る あうかな: HaskellのFunctorのおさらい あうかな: TemplateHaskellを調べてみた あうかな: btrfsを実際に触ってみた あうかな: Gentoo + nginx + FastCGI PHP で高速PHP環境を構築する
余裕であえますね。これっぽっちも切なくなんかない。
eしずおかからお酒のブログ
$ ./nk http://osake.eshizuoka.jp/index.xml きみにあうよ あうかな: 富士山、世界遺産登録勧告ということで あわない: チケット3日で完売の、焼津の酒イベント あわない: さぁ今日は無礼講だ!季節限定ベアード あわない: ZUNビールの味に近いベアード販売中 あうかな: 再々入荷しました!幻の米の臥龍梅 あわない: 豊田一丁目、倉庫火災出動 あうかな: お寺の庭のゆず♪ 季節限定ベアード あうかな: 【入荷】志太泉の普通酒が普通じゃない あうかな: 5.3 由比桜えびまつりヽ(゚∀゚)ノ あわない: 裏鈴木酒店 『とある酒屋の超萌酒会2』 あうかな: 【入荷】英君の特別純米の袋吊り雫だ あうかな: 【入荷】杉錦の誉富士山廃純米生原酒 あうかな: 再入荷しました♪ 臥龍梅の渡船! あわない: 駿河区にまた大型ショッピングセンター あわない: 眼鏡っ娘のめがね拭きができました! あわない: 焼津のあの娘(仮)の、大きめ画像 あうかな: お手頃♪ 臥龍梅、純米吟醸ワンカップ あうかな: 【再入荷】最後の、そに子の痛茶です! あうかな: 【入荷】臥龍梅。幻すぎる、短稈渡船だ あわない: 静鉄の長沼駅でさりげなく萌えてみる
萌えよりも日本酒ってことでしょうか?あと、ビールも飲めってことかな。
というわけで、適当に作ったわりには良い感じで分類できている気がしますね。
$ ./nk --help Nishino Kana Usage: nk ([-l <conf>|--learn=<conf>] | <url>) Options: -h --help show this screen -l <conf> --learn=<conf> training
設定ファイルはjsonです。kanaがあうほうでanakがあわないほうです。
{ "kana": ["http://127.0.0.1:5000/rss/"], "anak": [ "http://feedblog.ameba.jp/rss/ameblo/nishino-kana/rss20.xml", "http://feedblog.ameba.jp/rss/ameblo/yamamo-tomato/rss20.xml", "http://feedblog.ameba.jp/rss/ameblo/financilthory011/rss20.xml", "http://feedblog.ameba.jp/rss/ameblo/hazu-r72t/rss20.xml", "http://feedblog.ameba.jp/rss/ameblo/hitomi19800911/rss20.xml", "http://feedblog.ameba.jp/rss/ameblo/1983mayumayu/rss20.xml", "http://feedblog.ameba.jp/rss/ameblo/2pmoneday2/rss20.xml", "http://feedblog.ameba.jp/rss/ameblo/to-meee/rss20.xml", "http://feedblog.ameba.jp/rss/ameblo/sa-ku-ra-0706/rss20.xml", "http://feedblog.ameba.jp/rss/ameblo/taiyakisuki8/rss20.xml", "http://feedblog.ameba.jp/rss/ameblo/pikatyu-tyu/rss20.xml", "http://feedblog.ameba.jp/rss/ameblo/urakamimieko/rss20.xml", "http://feedblog.ameba.jp/rss/ameblo/wins-motomiya/rss20.xml", "http://feedblog.ameba.jp/rss/ameblo/taisukekmft2/rss20.xml" ] }
#!/usr/bin/env python # -*- coding: utf-8 -*- import feedparser import MeCab import re import json import nltk from docopt import docopt import pickle html_tag = re.compile(r'<[^>]+>') cmd = """Nishino Kana Usage: nk ([-l <conf>|--learn=<conf>] | <url>) Options: -h --help show this screen -l <conf> --learn=<conf> training """ def morph(entry): txt = html_tag.sub('', entry.summary_detail.value) words = [] try: t = MeCab.Tagger() m = t.parseToNode(txt.encode('utf-8')) while m: if m.stat < 2: if re.match('名詞', m.feature): words.append(m.surface) m = m.next except RuntimeError: pass return words def feed_parse(url): d = feedparser.parse(url) words = [] for entry in d.entries: words.extend(morph(entry)) return words def extract_features(document): documentwords = set(document) return dict([('contains(%s)' % word, True) for word in documentwords]) def learn(conf): c = json.load(open(conf), encoding="utf-8") kana = [] anak = [] for url in c["kana"]: kana.extend(feed_parse(url)) for url in c["anak"]: anak.extend(feed_parse(url)) training_documents = [(kana, "kana"), (anak, "anak")] train_set = nltk.classify.apply_features(extract_features, training_documents) classifier = nltk.NaiveBayesClassifier.train(train_set) with open("classifier.pickle", "wb") as f: pickle.dump(classifier, f) def test(url): classifier = pickle.load(open("classifier.pickle")) d = feedparser.parse(url) rcode = {"kana": "あうかな", "anak": "あわない"} total = 0 result = {"status": None, "entry": []} for entry in d.entries: doc = morph(entry) r = classifier.classify(extract_features(doc)) if r == "kana": total += 1 result['entry'].append((rcode[r], entry.title.encode("utf-8"))) if total > 3: result['status'] = "きみにあうよ" else: result['status'] = "きみにあわないよ" return result if __name__ == '__main__': args = docopt(cmd) conf = args.get('--learn') url = args.get('<url>') if conf: learn(conf) elif url: r = test(url) print r['status'] print for code, title in r['entry']: print "{}: {}".format(code, title)
尚、TDMを構築するのが面倒だったのでNLTKを使いました。
 Python for Data Analysis
Python for Data Analysis 入門 機械学習
入門 機械学習 パターン認識と機械学習 上
パターン認識と機械学習 上 入門 自然言語処理
入門 自然言語処理