
02032016 Python
prompt_toolkit がアツいというエントリを見かけて、おーアツい!と色々見てたらptpythonなるものを見つけた。
EmacsではJedi.elつかってるし、いいかもと思ったけど、職場の開発マシンは非力でもっさりしていたが家のmacbook airでは快適だった。
ipythonとの使い分けどうすればいいのだろうかと思った。
02032016 Python
prompt_toolkit がアツいというエントリを見かけて、おーアツい!と色々見てたらptpythonなるものを見つけた。
EmacsではJedi.elつかってるし、いいかもと思ったけど、職場の開発マシンは非力でもっさりしていたが家のmacbook airでは快適だった。
ipythonとの使い分けどうすればいいのだろうかと思った。
08122014 Python
去年の春とは異なり、今年はshizuokaではGoが盛り上がっていたみたいですが、富士川東ラインまで撤退してShizuoka.py #4を開催してきました。
時間が余りそうだったので、身内しかわからないようなやっつけLTを用意しましたが… jsないだろうとかいうツッコミは置いといてください。
Pythonコミュニティが東に移動したのは、とあるチームが三島に移転したり、東部の製薬企業の人たちがPythonを書き始めたりして静岡でやるよりも、三島とか富士のあたりでやるほうが都合が良くなったという理由が大きかったりします。
次回は沼津でやって懇親会をタップルーム(ベアードビール)にしようかなとか思っています。
メインの発表はIPython notebookの話をしてきましたがネタが皆無で、本当にIPythonの説明をするという… オープンなデータを使ってIPython notebookでデモをしてきました。
他の発表者のスライドはconnpassから。いろいろと勉強になりました。個人的にはpip-toolsとmarshmallowがツボった感じです。
おやつはたむら屋の団子をチョイスしておきました。

懇親会は筋肉系居酒屋で。

プロテインを補給しつつ、楽しく会話ができましたね。
来年も開催予定ですのでまたご参加ください。
01122014 Python
時間が余ったらみんなでCheck.IOでもやるか、飛び入りLTでもやりましょう☆
スライド作らなきゃなーとIPython Interactive Computing and Visualization Cookbookを読み直しているが、僕の利用シーンってipython notebook + pandas(plot)なので。
まぁ王道だけどw
 IPython Interactive Computing and Visualization Cookbook
IPython Interactive Computing and Visualization Cookbook対話的ビジュアライゼーションはSpotfireみたいな可視化ツールが優っているんだけど、要約統計量を表にして眺めたいとか、再現可能な形にして保存しておきたいとか行った場合はipython notebook+pandasは有用なのでそういった話をしようかなと思っています。
いや、もちろんRでもいいんですよ。でも、対話の末に完成したワークフローをwebサービス化しようと思ったらPythonのほうが便利なんですよね。
あと、エントリ書いてたらちょうどDMが来て@ando_ando_andoのScrapy話はなしになりました。
というわけで、発表を引き続き募集しております。
19112014 Python
移動平均を効率よく計算する方法を調べていてNumpyのas_stridedというのが出てきたのだが、ぱっと見てよくわからなかったので調べてみた。
とりあえずアレイを作る
import numpy as np from numpy.lib.stride_tricks import as_strided x = np.arange(10)
Int型なので8byte
print x.strides # (8,)
最初のタプルは作成する配列の次元。 次のタプルがよくわからなかったので調べたら、最初がrowのstrideで次がcolumnのstrideだった。
as_strided(x, (5, 6), (8, 8)) # array([[0, 1, 2, 3, 4, 5], # [1, 2, 3, 4, 5, 6], # [2, 3, 4, 5, 6, 7], # [3, 4, 5, 6, 7, 8], # [4, 5, 6, 7, 8, 9]])
100 numpy exercisesでもやっておいたほうがいいような気がしてきた。
それから、12/6にShizuoka.pyをやります。12/20にはShizuoka.goがあります。
Shizuoka.pyでは発表者絶賛募集中です☆
01112014 Python
@ando_ando_andoと一緒にコミュニティFでScrapyをいじっていた。
$ scrapy startproject tutorial
とかでひな形が作られるので楽なのと対話操作のためのユーティリティが用意されていてスクレイピングのチェックをするときに便利だなぁと。
.
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
├── __init__.py
└── yahoo_spider.py
こんな構成にして
import scrapy class YahooItem(scrapy.Item): name = scrapy.Field() total = scrapy.Field()
spiderのほうは
import scrapy from tutorial.items import YahooItem class YhSpider(scrapy.Spider): name = "yahoo" allowed_domains = ["yahoo.co.jp"] start_urls = [ "http://stocks.finance.yahoo.co.jp/stocks/detail/?code=4568.T" ] def parse(self, response): item = YahooItem() item['name'] = response.xpath('//title/text()').extract() item['total'] = response.xpath('//*[@id="main"]/div[7]/div[2]/div[2]/div[1]/dl/dd/strong/text()').extract() return item
とかやると、第一三共の時価総額をスクレイプできる。
@ando_ando_andoになんで自分の会社スクレイプしないん?とか言われたけどなんかいやじゃんw
ちょっと仕事で使ってみようと思ったので有意義なひとときであった。
それから、@karky7もウォーズアカウントを持っているらしいことを聞いたのでいつか手合わせしてもらわんとなぁとw
28102014 Python
ほぼ一年ぶりですがShizuoka.pyを富士でやります。
そしてほぼ一年前のShizuoka.pyでのスライドが先週突然ブックマされまくって???ってなった。
なお、Scrapyに関しては今度のShizuoka.pyで #A君 が発表するかもしれないとのこと。期待☆ 僕も自前のクローラーを新しくしたいのでちょっと勉強しようっと。
あと、入門的なセッション入れたほうがいいのかなーと思っているけどどうなんでしょう? とりあえずドットインストールでも読めばいいんじゃないでしょうか。
入門セッションいれるならCheck.IOのLibrary2.0を解きましょうくらいからかなぁ。
27092014 Python
connpassを用意したので参加登録お願いします。
発表者も絶賛募集中ですので@fmkz___まで。
僕はCytoscape+chemviz2の話かiPython notebookの話でもしようかなと考えています。
この本良さげ。多分買う
IPython Interactive Computing and Visualization Cookbook22092014 Python
kNN, Naibe Bayesm, SVM, (Random Forrest)をScikit-learnでやってみた。データはiPython NotebookでReSTで出力したものをpandocでmarkdown_strictに変換しなおしてblogに貼り付けた。
描画用のヘルパー関数とデータセットの生成
from matplotlib.colors import ListedColormap import Image from numpy import * from pylab import * import pickle def myplot_2D_boundary(X,y): x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02)) Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) plt.figure() plt.pcolormesh(xx, yy, Z, cmap=cmap_light) plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold) plt.xlim(xx.min(), xx.max()) plt.ylim(yy.min(), yy.max()) plt.show() with open('points_normal.pkl', 'r') as f: class_1 = pickle.load(f) class_2 = pickle.load(f) labels = pickle.load(f) X_normal = np.r_[class_1, class_2] y_normal = labels with open('points_ring.pkl', 'r') as f: class_1 = pickle.load(f) class_2 = pickle.load(f) labels = pickle.load(f) X_ring = np.r_[class_1, class_2] y_ring = labels with open('points_normal_test.pkl', 'r') as f: class_1 = pickle.load(f) class_2 = pickle.load(f) labels = pickle.load(f) X_normal_test = np.r_[class_1, class_2] y_normal_test = labels with open('points_ring_test.pkl', 'r') as f: class_1 = pickle.load(f) class_2 = pickle.load(f) labels = pickle.load(f) X_ring_test = np.r_[class_1, class_2] y_ring_test = labels cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA']) cmap_bold = ListedColormap(['#FF0000', '#00FF00'])
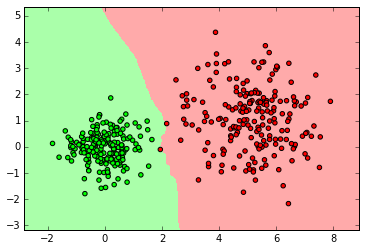
import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap from sklearn import neighbors, datasets clf = neighbors.KNeighborsClassifier(3) clf.fit(X_normal, y_normal) myplot_2D_boundary(X_normal,y_normal)
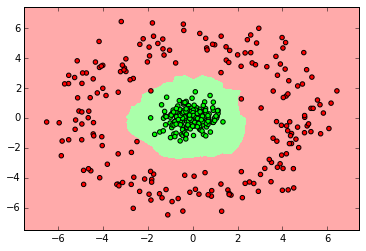
clf = neighbors.KNeighborsClassifier(3) clf.fit(X_ring, y_ring) myplot_2D_boundary(X_ring,y_ring)
from sklearn.naive_bayes import GaussianNB clf = GaussianNB() clf.fit(X_normal, y_normal) labels_pred = clf.predict(X_normal_test) print "Number of mislabeled points out of a total %d points : %d" % (y_normal_test.shape[0],(y_normal_test != labels_pred).sum()) myplot_2D_boundary(X_normal,y_normal)
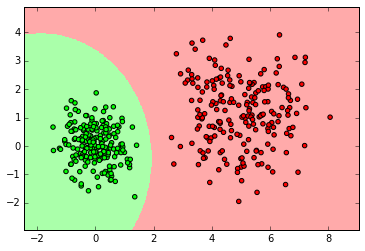
clf = GaussianNB() clf.fit(X_ring, y_ring) labels_pred = clf.predict(X_ring_test) print "Number of mislabeled points out of a total %d points : %d" % (y_ring_test.shape[0],(y_ring_test != labels_pred).sum()) myplot_2D_boundary(X_ring,y_ring)
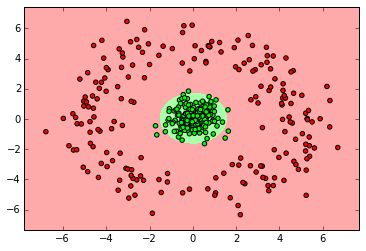
from sklearn import svm clf = svm.SVC() clf.fit(X_normal, y_normal) labels_pred = clf.predict(X_normal_test) print "Number of mislabeled points out of a total %d points : %d" % (y_normal_test.shape[0],(y_normal_test != labels_pred).sum()) myplot_2D_boundary(X_normal, y_normal)
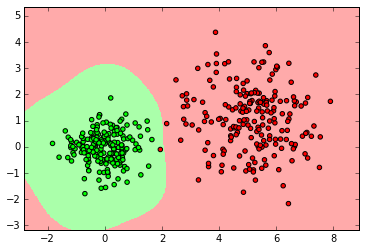
clf = svm.SVC() clf.fit(X_ring, y_ring) labels_pred = clf.predict(X_ring_test) print "Number of mislabeled points out of a total %d points : %d" % (y_ring_test.shape[0],(y_ring_test != labels_pred).sum()) myplot_2D_boundary(X_ring,y_ring)
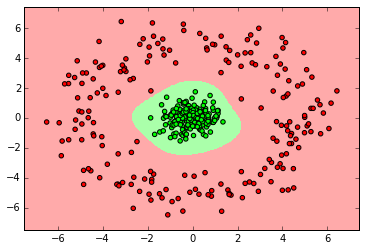
from sklearn.ensemble import RandomForestClassifier clf = RandomForestClassifier(n_estimators=10) clf.fit(X_normal, y_normal) labels_pred = clf.predict(X_normal_test) print "Number of mislabeled points out of a total %d points : %d" % (y_normal_test.shape[0],(y_normal_test != labels_pred).sum()) myplot_2D_boundary(X_normal,y_normal)
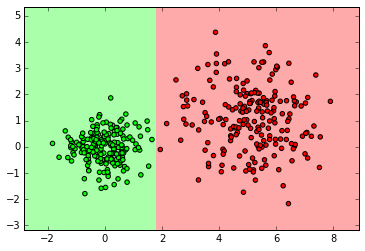
from sklearn.ensemble import RandomForestClassifier clf = RandomForestClassifier(n_estimators=10) clf.fit(X_ring, y_ring) labels_pred = clf.predict(X_ring_test) print "Number of mislabeled points out of a total %d points : %d" % (y_ring_test.shape[0],(y_ring_test != labels_pred).sum()) myplot_2D_boundary(X_ring,y_ring)
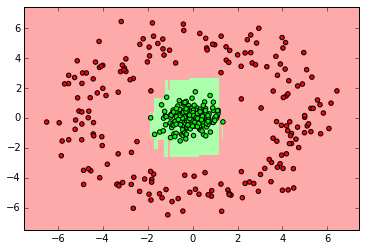
22092014 Python
最近ちょっと忙しくて実践コンピュータビジョンの読書会には初参加なのに発表してきたわけだが。
写経以外に務めたことはipython notebookとscikit-learnを推してきたw。あとディープラーニングの話とかしてた。そして少しまじめにディープラーニングを学ぼうと思った。
懇親会は筋肉居酒屋で。

店に入ると鉄アレイ等がお出迎え

塩バターラーメン風パスタ(一人前のハーフサイズw)

久しぶりに参加して楽しかったですね。主催者がいい感じにバトンタッチしつつ、新しい人も程よく入りながら長いこと続いているいい読書会だなぁと思いました。数えてみたらもうちょっとで5年ですね。
次回は島田でやるそうです。
22092014 Python
最近RHEL6を与えられたのだが、Pythonのバージョンが2.6系なので2.7系を入れつつ以下のパッケージを導入したのでメモ
開発環境をrpmで入れておく
yum groupinstall "Development tools"
yum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel
あとはPythonをソースからインストールする
wget https://bootstrap.pypa.io/get-pip.py python get-pip.py
scipyにはlapack(付きのnumpy)が必要なのだけどyum install blas,lapackは上手くいかないのでソースからインストールした。
wget http://www.netlib.org/lapack/lapack.tgz
tar xzfv lapack.tgz
cd lapack-*/
cp INSTALL/make.inc.gfortran make.inc
meke.incのオプションを修正する -fPICオプションを追加。もし64ビットマシンなら-m64オプションも追加
FORTRAN = gfortran OPTS = -O2 -frecursive -fPIC -m64 DRVOPTS = $(OPTS) NOOPT = -O0 -frecursive -fPIC -m64
書き換えたらmakeする
make blaslib; make lapacklib
出来た*.aを適当なディレクトリに配置して環境変数を設定し、.bashrcとか/etc/profileに追加しておく
export BLAS=/[path]/[to]/librefblas.a export LAPACK=/[path]/[to]/liblapack.a
pip install numpy
インストール出来たらblas,lapackが使われているかどうかを確認するためimport numpyしてnumpy.show_config()で確認しておく。
OKだったらscipyを入れる。
pip install scipy
libpngが必要なのでyumで入れる。それからRHEL6のfreetypeは2.3だがmatplotlib1.4.0でも動くので設定ファイルを書き換えてコンパイルする。
yum install libpng libpng-devel
1.4.0のソースをダウンロード
tar xvfz matplotlib-1.4.0.tar.gz
setupext.pyでfreetypeの2.4以上をチェックしているところを2.3に書き換える
python setup.py install
入れるだけ
pip install scikit-learn pip install pandas pip install patsy pip install ggplot pip install pyzmq pip install jinja2 pip install tornado pip install ipython