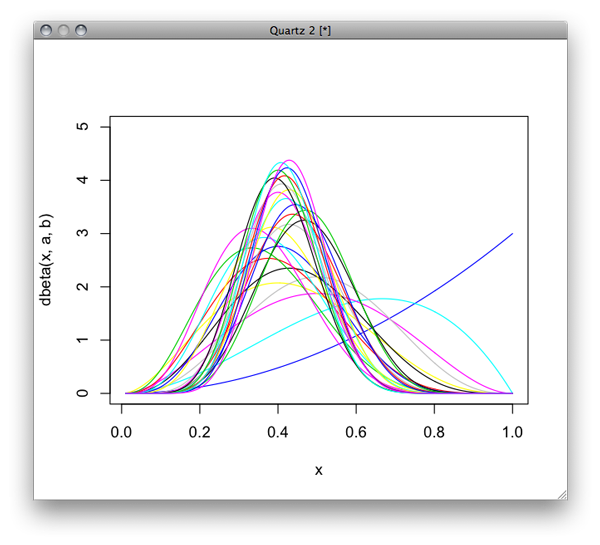
PRMLも再読してるが、手動かしながら読むほうがしっくりくる。 p.70のベータ分布の逐次学習ってのが面白そうなのでやってみた。
 パターン認識と機械学習 上 - ベイズ理論による統計的予測
パターン認識と機械学習 上 - ベイズ理論による統計的予測data <- rbinom(30,1,0.5)
plot_dbeta <- function(data){
a <- 0
b <- 0
x <- seq(0.01, 1.0, len = 500)
for (i in 1:length(data)) {
if(data[i] == 1) { a = a + 1 }
else { b = b + 1 }
if(i>3){
if(i==4){ plot(x, dbeta(x,a,b),type = "l",col=i,ylim=c(0,5)) }
else { plot(x, dbeta(x,a,b),type = "l",col=i,xlab="",ylab="",axes=F,ylim=c(0,5)) }
par(new=T)
}
}
}
二項分布で30個のリストを発生させて読みながらa,bのデータを更新していきつつその時のベータ分布の密度を求めつつプロットしていくという操作。
> data
[1] 1 0 1 1 0 0 0 1 0 0 0 1 0 0 1 1 1 0 1 0 0 0 1 0 0 1 0 1 0
[30] 1
データはこんな感じで、4番目のデータからプロットしていくとだんだん二項分布に近づいていく様がみてとれる。