
02082016 pokemongo
しあわせタマゴをつかって進化させまくった結果66500ポイントを獲得し、Lv22になった。
次のレベルまであと90000ポイントなのはIngress並w
ジム見るとLv24とかいてわけわからん。カイリュー、カビゴン、ラブラス欲しいけど一体だけゲットしても強化出来ないからシャワーズ戦隊にしたほうが効率がいい気がする。
02082016 pokemongo
しあわせタマゴをつかって進化させまくった結果66500ポイントを獲得し、Lv22になった。
次のレベルまであと90000ポイントなのはIngress並w
ジム見るとLv24とかいてわけわからん。カイリュー、カビゴン、ラブラス欲しいけど一体だけゲットしても強化出来ないからシャワーズ戦隊にしたほうが効率がいい気がする。
しあわせタマゴ+ポッポ進化のブースト使わなかったから3日くらいかかった。あと夏バテとポケバテでやる気のない日が1日ほどあったw
さらに、経験値よりは、いい感じのAR写真を撮る方に楽しみがシフトしているw

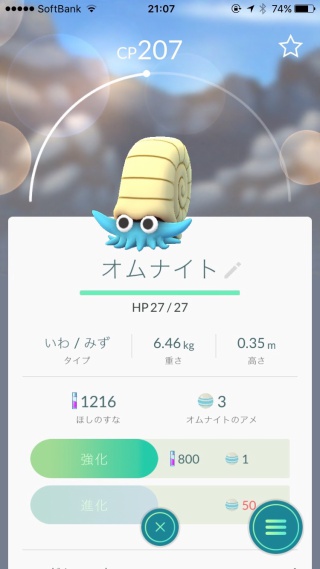
家にオムナイトが迷い込んできたので捕獲
ちょっと用があって静岡に行ってきた。駿府城でポケモン捕まえるぞーとか思っていたのだけど、暑すぎて断念したw
そもそも家をでる時点でこの富士山の状態がやばかった。静岡はやはり暑かった

久しぶりにコメヤスさんにでも行くかなーとぶらついたところ、美味しそうなラーメン屋さん発見。そして美味しかった。細麺の麺茹で35秒だったから、博多ラーメン的な麺なのに白濁した豚骨スープじゃなくてクドくない味でよい。替え玉もある。ここはつけ麺も美味しそうだった(麺は異なる)


用が済んだらまっすぐ帰る予定だったが、暑すぎて水分補給をせざるを得なかった。お茶エールを飲んだがあまりお茶感がなかった。


ところで、緑茶割りの緑茶はどのグレードの茶葉を使うのがいいのだろうか?
久しぶりに料理した。魚介のアヒージョと、鶏むねの塩レモンオーブン焼き。クスクスはサラダに使うよりもオーブン焼きの底に敷いたほうが好きかも。オーブン料理は入れっぱなしでいいのが楽なのでもう少しレパートリーを増やしたい。


コメヤスさんで19をゲット。酸が効いてて美味い。そして、日本酒が充実している居酒屋が富士にあるっていう話を聞いたんだけど、調べたら三島だった。今度行きたい。

28072016 pokemongo
IngressでいうところのLv8を達成した。大体一週間くらいか。

あるジムに挑戦するとGOって文字が大きくなるところでフリーズして強制終了、再起動で認証で5分くらい止まるというのを三回繰り返してイライラした。

あとは、ボール投げたら飛び出しちゃったからズリの実使おうとしたタイミングで雲隠れしちゃった場合フリーズするっていうのもバグかな。
ミニリュウゲットした。カイリュウまでの道は長いがのんびり育てるつもり。

27072016 pokemongo
60匹まとめて進化させるつもりだったのだけど…
夜、何故かカウントダウンするたまごが表示された。
それが「しあわせたまご」の効果だと気づいた時には既に10分以上経っていたという。(ポケットの中で勝手に使うことになってしまったようだ)
慌てて手元のポケモン進化させまくったのだけど、30000ポイントくらいにしかならなかったっぽくLv17->Lv18半分くらいまでしかあげられなかった。残りの分を息子と一緒に散歩してなんとか19にまであげて今日は終了。
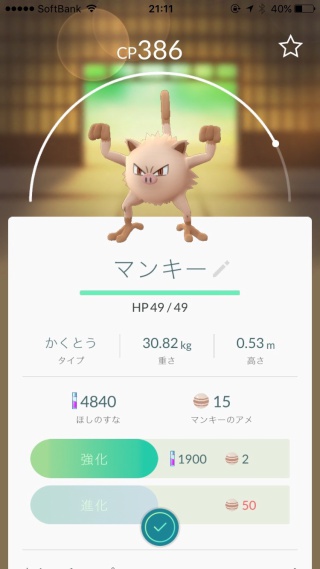
新しいポケモンは「カブト」「ゴース」「マンキー」
マンキーはキーキーうるさい息子にそっくりなので、息子の名前をニックネームにして育てることにしたw
それにしてもモンスターボールの枯渇は大問題だw 職場の周りにポケストップないから十分なボールを持って行かないと昼休みは孵化作業しかやれないのがツライw
23072016 pokemongo
昨日から始めてLV10にまで上げてみた。チームは青。

こんな感じでingressとは違ったまろやかさがあるから楽しいですね。

ただし、ジムにポコポコとポケモンのっけるだけでジム間の連携による面白さみたいなものがない。 ただ集めるだけだったらそのうち飽きるかなぁとしか思えない。バッジも基本的には集めたポケモンの数で決まる感じなので達成感は少ないかも。ingressみたいに勢力図の概念は欲しいなぁ。
尚、昨晩から近所のジムにLv24とLv22のプレーヤーがCP1400ゴダックとかCP1500ブースターとかCP1700シャワーズとかおいていて一体何なの?っていう… 運営の方でなんとかしてくんないかなぁ
22072016 ingress
前回のレベルアップからなんと10ヶ月…
前回レベルがあがってから、単にAPを稼ぐという作業がイヤになって離れていたのだけど、ウォーキングのために再開してから5ヶ月弱くらいかな。そしてトレッカーがプラチナになったので結構歩いたなぁと。トランスレーターもオニキスに行きそうなので続ければlevel16は見えているんだけどどうしたもんか(ウォーキングの延長としてもう少し頑張るかなぁ)
次のレベルもAP稼ぐだけだけど最近は家の周りは味方のポータルしかないからAP上げづらいんだよなぁ。L8バースターも400個くらい常にストックしてあるしなぁ…
といいつつポケモンGOを待ちわびているw
子供が仲良くしている同じマンションの家族と一緒にキャンプに行ってきた。
なんか色々作るのに忙しくて写真はほぼないw
チキンハウスで買った焼き鳥。ここのは美味しいのでオススメ。

焚き火をしながら、お酒を飲むのはいい。スノピのは重いのでユニフレームがいいと思う。あとは天子の森の薪はいまいち燃えが悪いということでみんなの意見が一致したw

ハンモックは、あるだけで子供の遊び場になるし、僕はハンモックに揺られてジャンプ読んだりしてたので、必須アイテムですね。安いので十分

ロープは長いのを別に用意しておいたほうが木の距離で悩まなくていいのでいいと思う。今回はラッキーなことに調度良い木があったけど、子どもたちには低いと文句を言われた(高いと落ちた時に危ないんだけどね)
13072016 work
久しぶりにビジネス本をめくった
ビジネス本はわかった気にさせるだけだからなぁ。とはいえ、わかっているヒトにはサマリーになるから悪いことはないんだけどね。
という使い古された言葉を丁寧に解説している。
10072016 curry
先日スパイスを挽いたので週末は僕のカレー力を発揮した。
金曜日はカレー欲が高まりすぎて早退してカレー作ったw
肉はかなり前に購入したイズシカにトゥナパハをふんだんに使用したココナッツベースのカレー+ターメリックライス。


チリパウダーもふんだんに使用したため子供ウケはいまいちだったが、自分のカレー欲は満たされた(のか?)
で、今日はガラムマサラのほうを使って、オクラ、舞茸、ナスのカレーを作った。

こっちも出来は良かったので満足。当初はゴーヤと豆腐のカレーにする予定だったんだけど娘に反対されたので変更(ゴーヤ苦手)
尚、子供にはカレー作りすぎって言われたけどお前ら完食してたじゃん…w
スパイスいじりも楽しいですな。
 ユニフレーム(UNIFLAME) ファイアスタンド2 683064
ユニフレーム(UNIFLAME) ファイアスタンド2 683064 OUTDOOR EX 2人用 耐荷重 200kg 布製 ハンモック 専用ポーチ 補強帯 S字フック 付 ストライプ(ブルー)
OUTDOOR EX 2人用 耐荷重 200kg 布製 ハンモック 専用ポーチ 補強帯 S字フック 付 ストライプ(ブルー) ドラッカー教授『現代の経営』入門 (ビジネスバイブルシリーズ)
ドラッカー教授『現代の経営』入門 (ビジネスバイブルシリーズ)