
blueprintと何が違うのかなと。
クラス名とメソッド名からURLが自動的に決められるのが、brueprintよりも便利かなぁ。
今度使ってみる。
08042013 Python
pythonで外部コマンドを叩くときにos.systemにするかcommands使うか迷ったりするんだけどpopenもあるしsubprocessもあって何使えばいいのかさっぱりわからん。
という状態だったんだけど、subprocessを使うのが正解らしい。
subprocess モジュールは新しくプロセスを生成して、そのプロセスを扱う一貫したインタフェースを提供します。それは従来からある他のモジュールよりも高レベルなインタフェースを提供します。そして os.system(), os.spawn(), os.popen(), popen2.() や commands.() のような従来の関数の置き換えを目的としています。
そんなわけでsubprocessを使っていこうと思った。
07042013 Python
今週末はShizuoka.pyなので、興味があれば参加してみてください。
僕はこの土日で発表資料大体作り上げ、あとは行くだけになったので気楽です。最近pythonでpptxを作ろうかと思っていてスライド作ってみたのでそれをLTに入れておきました。あとSphinxの話でもします。
それから、懇親会はPhotoに決まりましたので、現時点で参加が濃厚な方はお知らせください。
次回はこのスタイルでやるのがいいのか、ハンズオン入れていく感じのほうがいいのかは最後に時間が余れば、もしくは懇親会で議論しようかなと思ってます。
なんかはハンズオンするのにちょうどいいんじゃないかなぁと思っているけど。
06042013 Python
化合物の番号リストを入れたらデータベースからデータ取ってきて良い感じに並べて表にしてみたいな、サマリーを自動で作りたい。
あんな苦行みんなよくやるなぁと思っていたら、実際はみんなぶつくさ言いながらやってた。
pptxなんてxmlをzipで固めたやつだから展開して中のXML書き換えてまたzipで戻すサービスつくればいいじゃんと思いついたので作ってみたんだけど、なんかいまいちだったので放置してあった。
前者に関してはpython-pptxというパッケージがあるらしいのでこれを使えば解決しそう。ドキュメント読んだけど表の作り方は分からなかったのでソース読めばいいのかな。
問題は後者だけどどうしようかなー。
03042013 Python
python-livereloadのソース読んでたらdocoptというモジュールを使っていて、「optparseでもargparseでもないのか、なんだこれ?」と調べてみた。
optparse,argparseのようにオプションを登録してhelp,usageをつくるのではなく、helpの文字列からオプションをparseして組み立てるものだそうだ。
Command-line interface description language(CLI記述言語)と銘打っているので、python限定というわけではなく、Ruby,CoffeeScript,PHPなんかにも実装があるようだ。
cmd = """Python LiveReload Usage: livereload [-p <port>|--port=<port>] [-b|--browser] [<directory>] Options: -h --help show this screen -p <port> --port=<port> specify a server port, default is 35729 -b --browser open browser when start server """ def main(): args = docopt(cmd) port = args.get('--port') root = args.get('<directory>') autoraise = args.get('--browser')
使い方は簡単で、ヘルプの文字列書いたらdocoptに食わせるだけ。どの言語でも同じようにヘルプを書けるので嬉しいかも。積極的につかっていこうっと。
日本語の分かりやすい説明もあった。
30032013 Python
HaskellのHackageだと関数ごとにソースコードへのリンクがついていて便利。
Pythonで似たことやりたい時には、(pypi上ではソースコードを読めないので)、pydoc -pでブラウザからアクセスすればいいと思うのだけど
という状況なのでgit cloneしたコードをtmpディレクトリに置いてEmacsでetags付けて参照しするのが僕の最近のデフォなのだけど、さすがに効率悪いよなぁと思っているので改善したい。
なんかいい方法はないものか。
gitでpullしたらgunicorn restartできないかなと思って調べた。
supervisorctl status gunicorn | sed "s/.*[pid ]\([0-9]\+\)\,.*/\1/" | xargs kill -HUP
でrestartできるので、これを.git/hooks/post-mergeに書いておけばいいうようだ。
(あとでやる)
26032013 Python
あまり深く考えすにタイトルだけで購入したのだが、良い意味で裏切られた。でも分析の手法を期待して買うと退屈かもしれない。
この本はpandasの作者がそのライブラリの説明を事細かに語っているという内容です。
pandasは何かというと
Python has long been great for data munging and preparation, but less so for data analysis and modeling. pandas helps fill this gap, enabling you to carry out your entire data analysis workflow in Python without having to switch to a more domain specific language like R.pandas
データプレパレーションと分析のギャップを埋めるためのライブラリです。
具体的にはpythonに(Rでいう)dataframeを与えます。実際にはdataframeに加えてSQLでいうところのjoin(many-to-manyとかone-to-many,outer,inner)とかgroupingもできるし、multiindex(階層型のインデックス)もサポートしているので、使いやすい。
Rでデータの前処理をやる気にはなかなかならないと思うので、大体他の言語でデータを綺麗にしてからRにぶち込むという流れが多いと思うが、pandas+scipy+matplotlibを使えば分析までできるし、scikit-learnを利用すればさらに機械学習も可能。どうしてもRが使いたければrpy2使えばいい。
本の内容は5章くらいまでをipythonやnumpyの基本的な事柄に割いているのと、appendixになぜかpythonの基礎が載っているという状況なので、Rユーザーの置き換えを意識して構成されているのかなぁ?という感じ。8章はmatplotlibの説明。
5章からpandasの機能がずらずらと紹介されていてデータの要約のやり方とか、欠損値の扱い方とかデータの変換とかRでよくやるであろうことを丁寧に説明している。で、章の最後に実際の例が載っているんだけど、この部分は読んでて楽しい。
読んで覚えるというよりは、pandasを使っていてわからないことが出てきたらこの本をあたって理解するという使い方のほうがいいかもしれない。
本書を読んでpandasを積極的に使っていこうと思ったので、ググったらちょっと前にtokyo.scipyで事例紹介されていたみたいで、、、行きたかったなぁ。
昨日からFlask入門のやつをSphinxに移植していた。
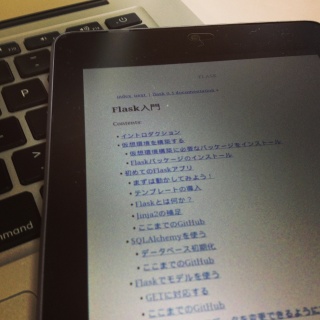
epubはさくっとmakeできたのだけど、Sphinx mobi builderにならってビルドしてみたけどNotImplementedErrorがでたので、Sphinxでmobiにするのは諦めてcalibreを使った。
Exception occurred: File "/Users/kzfm/Sphinx_projects/kindlebuilder/kindlebuilder/kindlewriter.py", line 295, in visit_image raise NotImplementedError("should implement this feature") NotImplementedError: should implement this feature
ちょっと負けた感があるので、Shizuoka.pyまでにはいい感じのmobi変換のやり方を見つけておきたい。あとSend to Kindle Buttonでmobiをkindleに送れるように設定できるのだろうか?できるのであればSphinxでつくったGitHub Pagesにmobi用のボタンつけることができてかなり快適になると思うんだけどなぁ。
というような内容のLTをやれればと思っているので、興味があればShizuoka.pyに参加よろしくお願いします。
 Python for Data Analysis
Python for Data Analysis